原创不易,转载请标明出处及原作者。

写在前面的话:文章介绍了深度学习模型在数据短缺时容易过拟合以及股票时间序列可能发生领域偏移的问题。为了解决这些问题,论文提出了一个名为MASSER的新颖框架,它结合了自监督学习和元学习,并通过两阶段表示学习来提高模型的泛化能力和适应性。MASSER框架在两个开源数据集上进行了广泛的实验,与现有最先进的基线模型相比,平均准确率提高了5%到9.5%。
第1章 引言
作者首先指出了深度学习模型在股票运动预测任务中面临的挑战,包括数据量有限导致的过拟合问题。为了解决这一问题,提出了利用预训练模型的方法,即在相关数据上预先训练模型以提高时间序列分类的性能。然而,由于股票之间存在显著的异质性,传统的迁移学习方法在股票预测中可能不适用。因此,需要一个能够快速适应所有股票且具有强泛化能力的框架。
作者讨论了股票市场预测中的时间模式领域偏移问题。在实际场景中,由于环境随时间演变,股票市场的数据分布可能会发生不可预测的变化,即存在非平稳性。这导致在模型训练和测试过程中需要特别关注领域偏移问题,包括如何在不同时间尺度内检测和处理领域偏移,以及如何在模型训练中考虑不同领域间偏移程度的重要性。
MASSER框架是一个结合了监督学习、自监督学习和元学习的股票预测框架。该框架通过两阶段表示学习来训练编码器,以提高对领域偏移的检测能力,并增强模型的泛化能力。MASSER在多个基准数据集上进行了广泛的实验,结果表明其在提高预测准确性和泛化能力方面优于现有的强基线模型。此外,MASSER还将股票运动预测的离线设置扩展到在线设置,允许在测试流数据中考虑可能发生的时序领域偏移,从而更接近真实的日内交易场景。
第2章 两阶段表示学习
第一阶段:宏观表示学习
在第一阶段,构建了一个基于时间卷积网络(TCN)的编码器,目的是学习数据集级别的统一表示。这个阶段的编码器通过提取对预测有用的特征,并匹配学习到的嵌入与相应预测标签之间的映射关系。损失函数是两个目标的凸组合:一是预测输入子序列的均方误差(MSE),用于训练模型精确预测;二是嵌入距离矩阵和标签距离矩阵之间的Frobenius范数差异,用于强制模型学习批次内嵌入和ROC预测标签的对齐。通过这一目标,具有相似ROC的子序列可以在潜在空间中彼此靠近。第二阶段:微观表示学习第二阶段的目的是使编码器对连续子序列之间的时间领域偏移更加敏感。通过对比学习进行时间领域检测,设置两个连续子序列作为双重窗口,训练第二阶段编码器以适应领域偏移检测。使用InfoNCE作为损失函数,最大化双重窗口的互信息。通过计算每个小批量嵌入的互信息,优化参数以正确分类正负样本对。第二阶段学习目标是最小化小批量内所有正样本对的二元交叉熵损失。利用这个编码器,计算输入中所有双重窗口的相似性,设置阈值以推断嵌入是否包含偏移
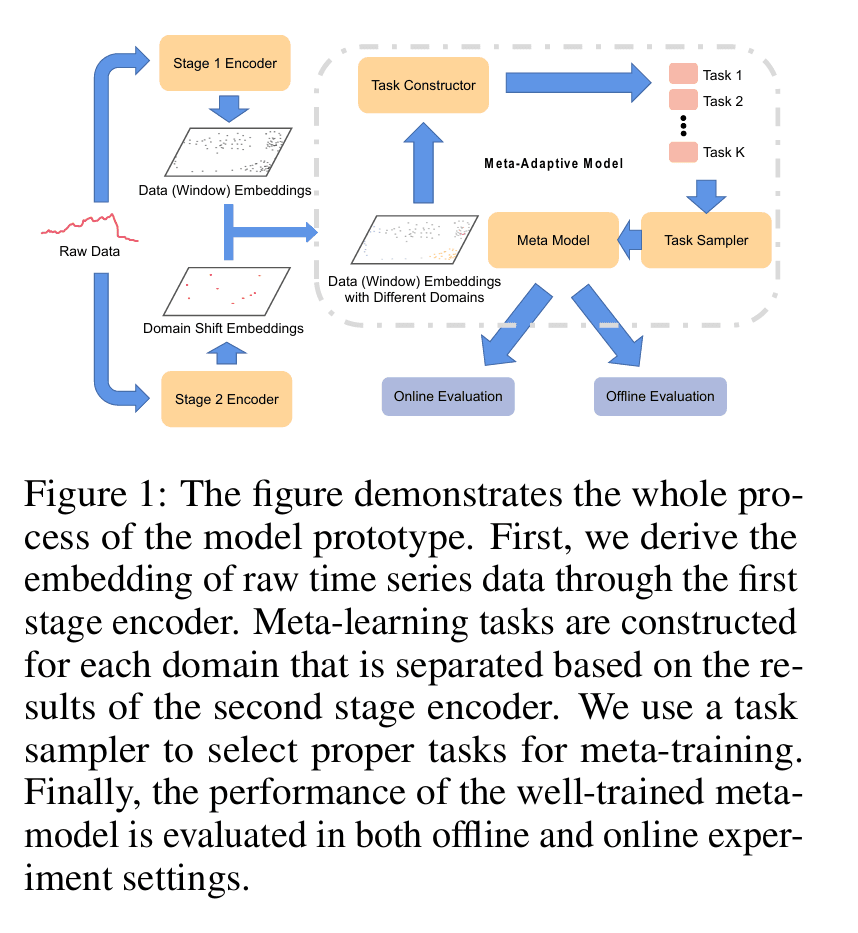
第3章 元自适应股票运动预测
本章深入讨论了MASSER框架的元学习组件,具体说明了如何使用两阶段编码器构建元学习任务,并对元模型进行领域偏移适应性训练,包括任务构造、质量评估和自适应抽样策略,旨在提升模型对时间序列中领域变化的泛化和适应能力。
第4章 实验结果
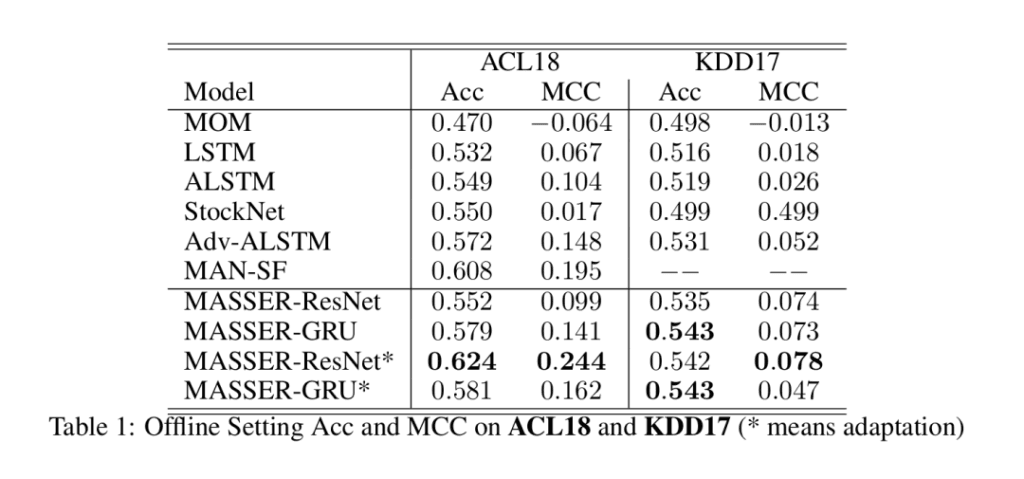
实验所使用的数据集和评估指标包括准确率(Acc)和马修斯相关系数(MCC),并选择了ACL18和KDD17两个公开的股票数据集进行模型性能的评估。在基线模型方面,MASSER框架与多个现有的股票运动预测模型进行了比较,包括MOM、LSTM、GRU、ALSTM、StockNet、Adv-ALSTM和MAN-SF。实验设置中,采用了四层TCN作为两阶段表示学习编码器,并选择了ResNet和GRU作为元模型架构,使用MAML算法进行参数更新。通过网格搜索确定了模型的最佳超参数。在离线实验中,MASSER框架在两个数据集上均展现出比基线模型更高的预测准确率和MCC,特别是经过适配的MASSER-ResNet模型在ACL18数据集上准确率提高了9.1%,MCC提高了64.9%;在KDD17数据集上准确率提高了2.3%,MCC提高了50.0%。
作者还展示了MASSER框架在在线实验设置中的表现,其中模型能够处理实时流入的数据,并在数据中实时更新模型参数。在线实验结果显示,MASSER-ResNet模型的准确率比基线模型平均提高了18.6%。此外,为了增强模型对在线数据流中潜在领域变化的适应能力,引入了贝叶斯在线变化点检测(BOCPD)来辅助检测领域偏移。通过消融研究,验证了MASSER框架中各个组成部分的有效性,证明了完整框架在所有变体中表现最佳。这些实验结果共同证明了MASSER框架在股票运动预测任务上的有效性,尤其是在提高预测准确性和对时序领域偏移的泛化能力方面。
第5章 结论
本文总结了MASSER框架的主要贡献,并强调了其在股票运动预测方面的优越性能,特别是在自监督学习和元学习结合的方法下,有效地处理了时间序列中的领域偏移问题。此外,章节提出了两阶段表示学习策略,通过构建任务、评估任务质量并自适应地抽样任务来提高模型的泛化能力。
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
转发请注明原作者和出处。
Be First to Comment