作者:老余捞鱼
原创不易,转载请标明出处及原作者。
写在前面的话:在人工智能与数字金融不断融合的今天,量化交易正迎来一场革命。微软的开源量化平台Qlib,凭借全流程支持、自动化工作流和多种先进算法,为投资者和研究者提供了一个低门槛、高效率的量化投资解决方案。本文将带你深入了解Qlib的诞生、优势、颠覆性影响,以及基于Qlib构建的NVIDIA股票交易策略和全工作流配置的案例,最后探讨Qlib这类开源平台带来的未来机遇。
前几天我写了一篇题为:未来的量化交易主舞台,属于AI与开源共舞!的文章,引起了大家广泛的关注和讨论。借此机会,我想向大家介绍这场”AI与开源共舞”舞台上的首位舞者——微软Qlib平台。
一、Qlib的前世今生
微软亚洲研究院于2020年9月正式开源了业界首个 AI 量化投资平台——Qlib,并在 GitHub 上开放了全部源代码,而且还在持续更新(最后一次更新是今年春节前)。Qlib旨在打造一个通用技术平台,实现从数据处理、模型训练、策略回测到投资组合优化的 AI 闭环。
它的推出不仅展现了AI在金融科技领域的强大潜力,更体现了开源精神在推动行业进步中的关键作用。这个平台的出现,标志着量化交易正迈向一个崭新的时代,其中AI与开源技术的协同创新将成为驱动行业发展的核心动力。
开源地址:https://github.com/microsoft/qlib
关于Qlib的报道网上很多,这里就不再赘述了。我想大家更想了解的是这几年来微软开源Qlib后的实际用的如何。
1.1 成功案例与实践应用
这几年来,Qlib平台在多个场景中都有出色表现,下面列举几个成功案例:
- 强化学习在订单执行中的应用
利用多智能体协作强化学习(MARL)方法,Qlib在订单执行优化上取得突破,有效减少决策冲突并提升整体利润。 - 高效数据存储与计算优化
采用创新数据存储方案后,Qlib在存储空间占用和因子计算效率上均超越传统数据库(如MySQL、MongoDB),极大提高了数据处理速度。 - 华泰金工团队的实践经验
华泰金工的林晓明团队在实践中应用Qlib,认为其涵盖了量化投资全流程,并在数据存储和计算效率方面表现卓越,为策略开发提供了强大支持。 - 学术研究与教育培训
多所高校和研究机构利用Qlib进行量化交易理论验证与教学实践,帮助学生在真实数据环境中掌握量化策略,实现理论与实践的高效对接。
1.2 四年来的应用效果如何?
自Qlib发布至今已过去四年多,其实际应用效果主要体现在以下方面:
- 提高效率与降低开发成本
通过全流程支持和高性能底层架构,用户无需频繁切换工具包即可完成量化研究,显著降低了算法使用门槛。 - 创新解决方案落地
Qlib在数据存储、因子计算等方面提出的创新解决方案有效缓解了传统量化策略开发中的性能瓶颈,缩短了策略迭代周期。 - 实战效果显著
多种AI模型(例如GNN和LightGBM)在实盘回测中展现了优异的超额收益,部分策略在沪深300等主流市场中表现尤为抢眼。 - 促进生态共建
开源的特性让Qlib成为量化投资领域的公共基础设施,推动了技术共享与社区发展,进一步激发了创新活力。
以上应用效果、成功案例和实践应用信息是从以下互联网报道中收集:
- 新浪财经:微软亚洲研究院开源Qlib
- 华泰研究院报告:Qlib开源平台解析
- 知乎问答:Qlib的实际应用效果如何?
- 聚宽Demo:Qlib实战应用案例
- 头条:Qlib平台的最新进展
- 网易财经:Qlib平台助力量化投资
- CSDN专栏:Qlib平台的全面解析
二、Qlib 功能介绍
Qlib专注于量化金融领域。它提供了一整套的工具和框架,支持数据处理、特征工程、模型训练和策略回测等功能。Qlib的设计理念是将复杂的量化研究流程简化,使得用户能够更专注于策略的开发和优化。
2.1 Qlib 核心功能概览
Qlib提供了一整套覆盖量化投资全流程的解决方案,其主要功能包括:
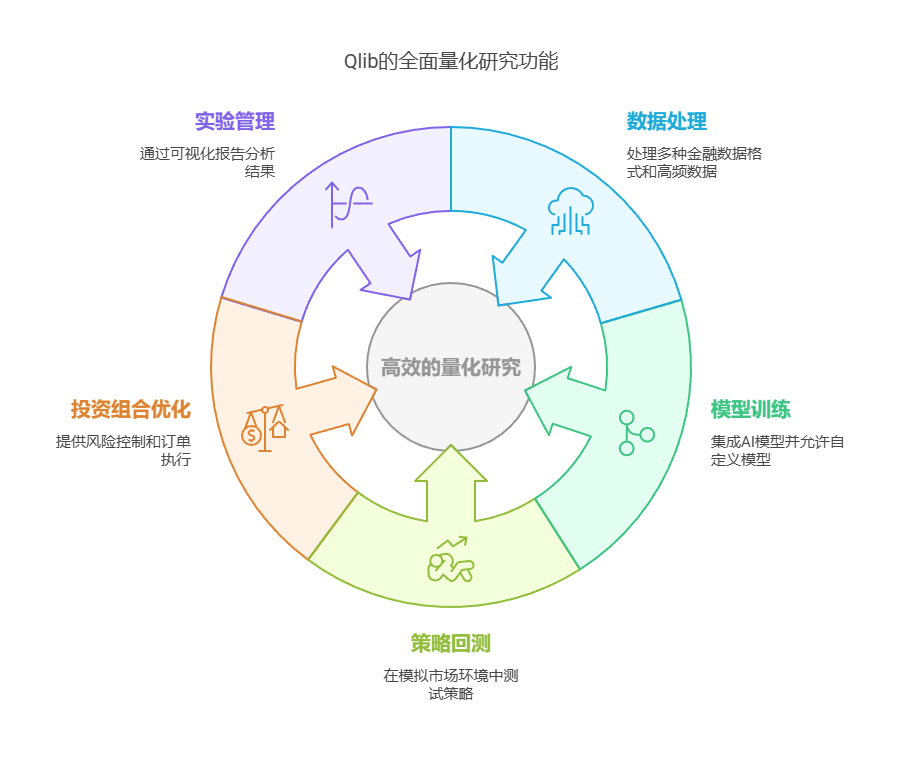
- 数据处理:
支持多种金融数据格式及高频数据处理,内置丰富的特征工程与数据清洗工具。 - 模型训练:
内置常用AI模型,同时支持用户自定义模型的灵活集成。 - 策略回测:
完善的回测系统模拟真实市场环境,支持多种回测模式和策略参数设置。 - 投资组合优化与订单执行:
从策略生成到风险控制,提供一站式解决方案。 - 实验管理与结果分析:
通过Jupyter Notebook展示详细图形报告,包括回测曲线、收益分布和风险指标等。
2.2 为什么选择 Qlib?
Qlib平台的设计初衷就是为金融从业者提供一个全流程、一站式的量化交易解决方案。
以下几点进一步阐释了其易用性与高效性:
- 开源与易用性: Qlib 完全开源,基于 Python 开发,API 简洁直观,无论是初学者还是专家都能快速上手。
- 全流程集成: 数据处理、模型训练、策略回测、投资组合优化等全链路功能一站式解决,免去繁琐的数据和工具切换。
- 自动化工作流: 利用
qrun工具,一键启动整个量化研究流程,极大提升研发效率。 - 模块化设计: 各功能模块松耦合,用户可以根据需求灵活组合和扩展。
三、Qlib如何颠覆传统量化交易
正如官方文档所描述,Qlib通过模块化设计和自动化工作流,改变了传统量化交易模式。下面从以下三个方面给大家说下我的理解,并附上关键代码示例。
3.1 全流程支持
数据处理:
Qlib内置丰富的数据接入、清洗和预处理工具,支持股票、期货等多种金融工具的历史行情、基本面数据及高频数据处理。
示例代码:
import qlib
from qlib.data import D
from qlib.config import C
from qlib.utils import init_instance
# 设置 Qlib 数据存储路径,并初始化环境
C["qlib_home"] = "./qlib_data"
init_instance()
# 加载Apple股票日线数据:收盘价和成交量
df = D.features(["AAPL"], fields=["$close", "$volume"], freq="day")
print(df.head())模型训练:
平台提供灵活的API接口和内置多种先进模型(如LightGBM、LSTM、Transformer等),支持用户自定义模型开发。
示例代码:
from qlib.contrib.model.gbdt import LGBModel
from qlib.workflow import R
# 定义模型参数
model = LGBModel(
loss="mse",
num_leaves=64,
learning_rate=0.01,
n_estimators=100,
)
# 构建数据集
train_data = D.dataset(
instruments=["AAPL"],
fields=["$close", "$volume"],
freq="day",
)
# 训练模型
model.fit(train_data)
# 保存训练好的模型
R.save_object(model, "trained_model.pkl")策略回测:
利用内置回测系统模拟真实市场环境下的交易情况,帮助评估策略有效性。
示例代码:
from qlib.contrib.evaluate import backtest
# 定义回测参数
backtest_config = {
"strategy": {"buy_threshold": 0.01, "sell_threshold": -0.01},
}
# 执行回测
performance = backtest(trained_model=model, config=backtest_config)
print(performance)3.2 AI技术集成
多种机器学习算法:
Qlib集成了LightGBM、LSTM等模型,支持监督学习、强化学习及元学习等多范式建模。
自动化研究流程:
借助qrun工具,整个量化研究流程(数据加载、模型训练、策略回测及结果评估)实现自动化运行。
例如,通过以下命令调用预先配置好的工作流文件即可启动整个流程:
qrun workflow_config.yaml3. 3 降低使用门槛与提高效率
- 开源与易用:
完全开源的特性使得初学者也能快速上手,基于Python开发,API设计简洁明了。 - 模块化设计:
每个组件相对独立,用户可以根据需求灵活组合和替换模块,降低开发与维护成本。 - 自动化工作流:
使用qrun工具可实现从数据采集到策略评估的全流程自动化,极大提高工作效率。
四、实践案例
案例1:基于 Qlib 的 NVIDIA 股票交易策略
以 NVIDIA(NVDA)为例,我们构建一个基于波动率交易策略的示例:利用 LSTM 模型对未来趋势进行预测,并在预测显示潜在下跌风险时执行卖出看跌期权(Put Spread)策略。以下为示例代码:
import qlib
import numpy as np
from qlib.data import D
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
# 初始化 Qlib,假设数据存储在指定路径(以美股数据为例)
qlib.init(provider_uri='~/.qlib/qlib_data/us_data')
# 加载 NVIDIA 的日线数据(收盘价与成交量)
nvda_df = D.features(["NVDA"], fields=["$close", "$volume"], freq="day")
print("NVDA Data Head:\n", nvda_df.head())
# 提取收盘价并归一化
data = nvda_df["NVDA"]['$close'].values
data_norm = (data - np.min(data)) / (np.max(data) - np.min(data))
# 构建 LSTM 数据集:使用过去 10 天数据预测第 11 天的收盘价
def create_dataset(data, window_size=10):
X, y = [], []
for i in range(len(data) - window_size):
X.append(data[i:i+window_size])
y.append(data[i+window_size])
return np.array(X), np.array(y)
window_size = 10
X, y = create_dataset(data_norm, window_size)
X = X.reshape((X.shape[0], window_size, 1))
# 构建 LSTM 模型
model = Sequential()
model.add(LSTM(50, input_shape=(window_size, 1)))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mse')
# 训练模型(示例中仅训练 10 个 epochs)
model.fit(X, y, epochs=10, batch_size=16, verbose=1)
# 对最新一组数据进行预测
latest_data = X[-1].reshape(1, window_size, 1)
predicted_norm = model.predict(latest_data)
print("Predicted normalized close price:", predicted_norm)
# 假设交易逻辑:若预测值低于 0.4,视为下跌信号,执行卖出看跌期权(Put Spread)策略
if predicted_norm < 0.4:
print("信号:预测显示未来可能下跌,建议执行卖出看跌期权(Put Spread)策略。")
else:
print("信号:无显著下跌风险,建议维持现有仓位。")说明:以上代码为示例,实际策略中可能需要更多因子、多模型融合以及风险管理模块的支持。
案例2:完整工作流配置示例
以下代码示例展示了如何构建完整的工作流配置,并通过qrun自动运行整个策略流程。工作流文件通常采用YAML格式保存,包含数据集、模型及回测配置。
工作流配置示例(workflow_config.yaml):
qlib_init:
provider_uri: "~/.qlib/qlib_data/cn_data"
region: cn
market: &market csi300
benchmark: &benchmark SH000300
data_handler_config: &data_handler_config
start_time: 2008-01-01
end_time: 2020-08-01
fit_start_time: 2008-01-01
fit_end_time: 2014-12-31
instruments: *market
port_analysis_config: &port_analysis_config
strategy:
class: TopkDropoutStrategy
module_path: qlib.contrib.strategy.strategy
kwargs:
topk: 50
n_drop: 5
backtest:
limit_threshold: 0.095
account: 100000000
benchmark: *benchmark
deal_price: close
open_cost: 0.0005
close_cost: 0.0015
min_cost: 5
task:
model:
class: LGBModel
module_path: qlib.contrib.model.gbdt
kwargs:
loss: mse
colsample_bytree: 0.8879
learning_rate: 0.0421
subsample: 0.8789
lambda_l1: 205.6999
lambda_l2: 580.9768
max_depth: 8
num_leaves: 210
num_threads: 20
dataset:
class: DatasetH
module_path: qlib.data.dataset
kwargs:
handler:
class: Alpha158
module_path: qlib.contrib.data.handler
kwargs: *data_handler_config
segments:
train: [2008-01-01, 2014-12-31]
valid: [2015-01-01, 2016-12-31]
test: [2017-01-01, 2020-08-01]
record:
- class: SignalRecord
module_path: qlib.workflow.record_temp
kwargs: {}
- class: PortAnaRecord
module_path: qlib.workflow.record_temp
kwargs:
config: *port_analysis_config配置好工作流后,只需在命令行运行以下命令,即可自动启动整个量化研究流程:
qrun workflow_config.yaml运行完成后,系统会生成详细的策略报告(包括回测曲线、收益分布、IC分布等),你也可以使用Jupyter Notebook查看更直观的图形化分析结果。
五、观点总结
随着人工智能和大数据技术的不断突破,量化交易将迎来更智能、更高效的发展时代。通过Qlib和NautilusTrader这些开源平台的出现,我们可以清晰地看到,未来量化交易的发展将不再局限于单一技术的突破,而是AI算法与开源生态系统的有机结合。这种融合不仅能够加速金融科技的创新步伐,还将为量化交易带来更多可能性,推动整个行业向着更智能、更开放的方向迈进。
- 深度融合更多前沿 AI 模型,提升策略预测准确率。
- 扩展至更多市场和资产类别,实现全球化量化交易。
- 加强与高频交易、期权交易等领域的结合,构建更全面的投资决策体系。
- 推动开源生态建设,促进量化投资领域的技术共享与协同创新。
- 探索自动化风险控制和实时策略调整,实现真正的智能量化交易。
展望未来,AI与量化交易的深度融合将为投资决策带来更高精度、更低风险的全新模式。
感谢您阅读到最后,希望这篇文章为您带来了新的启发和实用的知识!如果觉得有帮助,请不吝点赞和分享,您的支持是我持续创作的动力。祝您投资顺利,收益长虹!如果对文中内容有任何疑问,欢迎留言,我会尽快回复!
本文内容仅限技术探讨和学习,不构成任何投资建议。
Be First to Comment