作者:老余捞鱼
原创不易,转载请标明出处及原作者。
本文约 3800 字 | 阅读预计需 15 分钟,建议先收藏
写在前面的话:读完全文后,你将搞清楚:时间序列到底是个什么东西、为什么模型给出的预期值几乎总是错的、驱动时间序列分析的三大核心任务、从原始数据到交易信号的完整实现流程、以及导致90%的时间序列模型在碰真钱之前就失效的那个关键陷阱。
一、时间序列到底是什么?
时间序列,说白了就是按固定时间间隔记录下来的一串观察值。股票每天的收盘价、气温每小时读数、每月失业率数字。这些都是按时间索引排列的一组数值。
这个定义技术上没错,但实际用处不大。
大多数人忽略的关键点是:每一个时间序列都是由某种东西生成的。
一只股票的价格走势不是凭空冒出来的,它是数以百万计的投资人决策、算法执行、宏观经济力量共同作用的结果,这些因素你无法仅从价格序列上直接观察到。经济学家把价格叫做“内生变量”,真正驱动它的是那个看不见的数据生成过程。
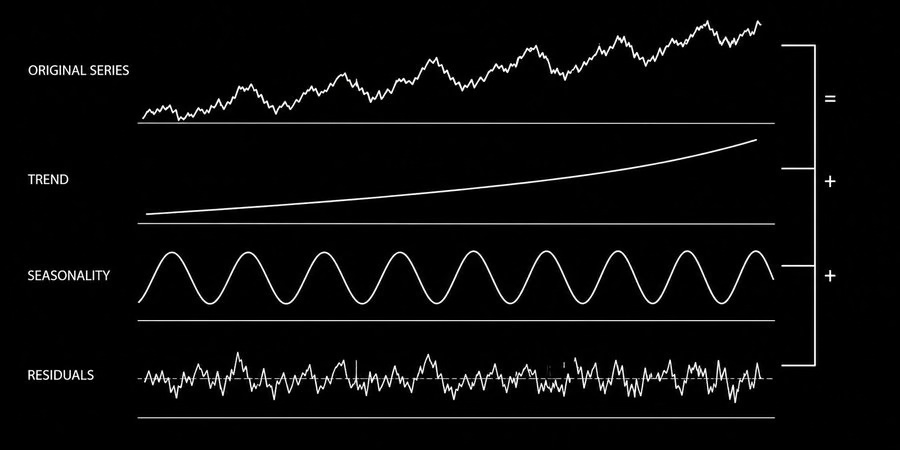
图:时间序列由趋势、季节性和随机冲击三部分组成
任何一个时间序列都可以拆解成三个成分:
| 成分 | 含义 | 市场中的例子 |
|---|---|---|
| 趋势 (Trend) | 长期方向性运动 | 指数长期上行/下行轨迹 |
| 季节性 (Seasonality) | 固定间隔重复出现的模式 | 月度销售周期、季度财报效应、周内成交量规律 |
| 冲击/残差 (Shock) | 围绕趋势和季节性的随机波动 | 突发事件、新闻、意外消息 |
关于趋势和季节性,有一个非常关键的认知:它们只有在稳定的时候才有意义。
如果一只股票的趋势每几个小时就反转一次,那趋势成分对你来说没有任何参考价值。稳定性是任何时间序列模型具备前瞻价值的前提条件。
打个比方:假设现在是12月的纽约,当前气温零下6摄氏度。如果让你猜明天的温度,你大概会说还是差不多零下几度上下。你不是在做精确预测,你是基于当前状态和已知的季节模式给出一个期望值。这个期望值在正常情况下是对的。
但如果冰岛突然火山爆发,全球气温一周内飙升8摄氏度呢?你的温度预测会严重偏离。不是因为模型不好用了,而是因为生成数据的底层过程发生了变化,而这种变化在温度序列上是完全看不到的。
这跟2008年抵押贷款证券的情况一模一样。价格序列看起来一切正常,但底层的真实信用状况已经变了。关键信息根本不在价格序列里面。
老余提醒:拿你现在关注的任意一个品种,用一句话写下你认为驱动它价格变动的最主要因素是什么。那个因素就是你使用任何时间序列模型时必须同时监控的东西。一旦它变了,你的模型就得重建。
二、为什么预期值总是”错”的?
所有时间序列分析的应用都逃不出三个类别。搞清楚你在做哪一类,能帮你避开量化金融里最常见也最昂贵的一个坑。
任务一:滤波 (Filtering)
滤波是用过去和现在的数据来估计系统的当前状态。你要做的是剥离噪声,看清现在到底在发生什么。
移动平均线就是一个滤波器。它不预测未来,它只是告诉你过去一段时间的平均水平是多少。你在交易软件图表上放的每一个指标,本质上都在做某种形式的滤波工作。当你放上一条20日均线时,你实际上是在说:”我想看看这个资产剥离了短期噪声之后的真实状态。”就这么简单。
任务二:平滑 (Smoothing)
平滑是用过去和未来的数据来估计某个历史时刻的状态。它需要用到”后视信息”,也就是说你需要知道一个时间点之后发生了什么,才能最好地刻画那个时间点当时的状态。
平滑对分析历史数据和构建研究数据集很有用,但它不能直接用于实时交易决策,因为它需要未来的信息。
任务三:预期 (Forecasting)
预期是用当前和过去的状态来产生一个关于未来的期望值。这是大多数人最关注的地方,也是误解最集中的地方。
E[Xₜ₊₁ | X₁, X₂, …, Xₜ]
上面这个公式就是条件期望,给定到目前为止所有观测值的情况下,下一个值的数学期望。
这里有一个绝大多数交易类教育都不愿意明确说出来的真相:
预期 ≠ 预测。它们不是一回事。期望值是在所有可能未来结果中使均方误差最小的那个单一数值。当你掷一枚公平骰子时,期望值是3.5。骰子能掷出3.5吗?不能。但3.5仍然是你做决策时最有用的数字,因为它是长期滚动中使你的平均误差最小化的值。
市场预期的工作方式完全一样。你的模型根据已有信息产生最佳期望值。这个期望值基本上永远不会等于最终实现的价格。但只要它在平均意义上是对的,而且你能系统地利用这一点,就能产生持续性的收益。
这正是做市商的运作方式。他们不需要知道价格确切会去哪。他们需要知道期望价格,然后在周围报出买卖价差,通过数千笔交易的积累来获利。
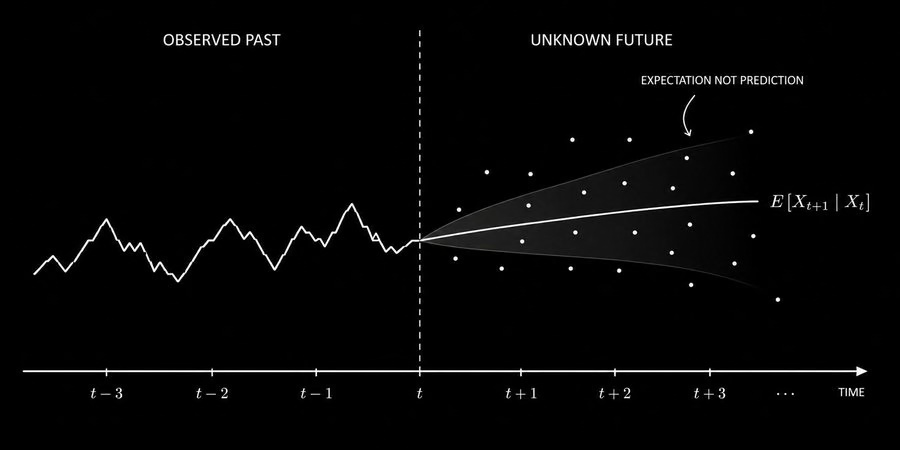
图:预期是条件期望,是使误差最小化的单一值,它几乎永远不等于实际值
核心结论
系统化交易使用时间序列分析的核心逻辑是:你不需要完美的预期值,你只需要在平均意义上正确的预期值,并且频率高到足以覆盖交易成本。同时你需要一套严格的框架来判断模型什么时候不再”近似正确”。
三、单位根陷阱:毁掉大多数模型的隐形杀手
这一节的内容能帮你避开量化金融中最常见、代价最高的错误:在非平稳数据上跑回归模型。
很多人想给股价建预测模型,第一步就是拿昨天的收盘价去回归今天的收盘价。跑完之后发现R方超过0.99,觉得自己发现了近乎完美的预测关系。
然而,他们掉进了统计学里最著名的陷阱之一:伪回归(Spurious Regression)。
实际情况是这样的:把同样的回归换成日收益率来跑,R方会从0.99骤降到大约0.01。从解释99%的变异变成只能解释1%。同样的标的、同样的数据、同样的模型结构,结果天差地别。
原因就是单位根(Unit Root)。
当一个时间序列的当前值等于前一个值加上一个随机扰动时,它就存在单位根:
Xₜ = Xₜ₋₁ + εₜ
这就是所谓的随机游走(Random Walk)。股价大致服从这个过程。当你拿一个随机游走去回归另一个随机游走时,即使两者毫无关系,你也几乎总能发现很强的统计相关性。这就是伪回归,它是无数虚假交易信号的来源。
检验这个问题的工具叫ADF检验(Augmented Dickey-Fuller Test)。它的原假设是序列存在单位根(非平稳)。如果p值小于0.05,你可以拒绝原假设,说明序列大概率是平稳的。如果p值大于0.05,那这个序列很可能有单位根,直接在上面跑回归会产生虚假结果。
# ADF平稳性检验完整示例
import numpy as np
import pandas as pd
import yfinance as yf
from statsmodels.tsa.stattools import adfuller
import warnings
warnings.filterwarnings('ignore')
# 1. 获取数据
ticker = yf.Ticker("SPY")
df = ticker.history(period="5y", interval="1d")
# 2. 准备序列
price = df['Close'].dropna()
# 普通收益率(也可以用对数收益率,结论一致)
returns = df['Close'].pct_change().dropna()
# 对数收益率(更常用)
log_returns = np.log(df['Close'] / df['Close'].shift(1)).dropna()
# 3. 执行ADF检验
price_test = adfuller(price, autolag='AIC')
returns_test = adfuller(returns, autolag='AIC')
log_returns_test = adfuller(log_returns, autolag='AIC')
# 4. 输出结果
print("=" * 50)
print(f"Price ADF p-value: {price_test[1]:.6f}")
print(f" → {'平稳' if price_test[1] < 0.05 else '非平稳(存在单位根)'}")
print("-" * 50)
print(f"Returns ADF p-value: {returns_test[1]:.6f}")
print(f" → {'平稳' if returns_test[1] < 0.05 else '非平稳(存在单位根)'}")
print("-" * 50)
print(f"Log Returns ADF p-value: {log_returns_test[1]:.6f}")
print(f" → {'平稳' if log_returns_test[1] < 0.05 else '非平稳(存在单位根)'}")
print("=" * 50)你会发现:价格序列通不过ADF检验,收益率序列可以通过。这说明永远不要在原始价格水平上构建预测模型。一定要先转换成收益率、对数收益率或其他平稳形式,然后再应用时间序列模型。
将价格序列转换为平稳序列的方法叫做一阶差分:
rₜ = ln(Pₜ) — ln(Pₜ₋₁)
对数收益率大致是平稳的,不过金融收益率序列仍然存在一些纯平稳性无法完全捕捉的特征,比如厚尾效应,我们后面在GARCH部分会讲到。
| 对比维度 | 原始价格序列 | 收益率序列 |
|---|---|---|
| ADF检验p值 | > 0.05(通常) | < 0.05(通常) |
| 平稳性 | 非平稳(存在单位根) | 近似平稳 |
| 回归R方 | 虚高(0.99+) | 真实水平(接近0) |
| 能否用于建模 | 不行!会产生伪回归 | 可以 |
老余提醒:检查一下你现在用的或者以前用过的任何交易模型,看它是建立在价格水平上还是收益率上的。如果是价格水平,对底层数据跑一下Dickey-Fuller检验。如果p值大于0.05,你的回测结果大概率被伪相关 inflate 了。四、真正管用的模型家族:AR / MA / ARMA / GARCH
现在你已经理解了时间序列的本质、三大核心任务和单位根问题。接下来我们来看那些在实际市场中真正有效的模型。
构成系统化交易骨干的模型族是ARMA及其扩展。这个家族中的每个成员捕捉的是金融时间序列中不同方面的序列依赖结构。
4.1 AR模型:自回归模型
p阶自回归模型写作AR(p),说的是当前值是其自身过去p个值的线性组合加上一个随机冲击:
Xₜ = φ₁Xₜ₋₁ + φ₂Xₜ₋₂ + … + φₚXₜ₋ₚ + εₜ
φ系数就是自回归参数。它们捕捉的是当前值有多少成分来自过去的值。
在交易中,AR模型适合捕捉短期动量和均值回复动态。φ₁为正的AR(1)模型捕捉的是动量;φ₁为负的AR(1)模型捕捉的是均值回复。
4.2 MA模型:滑动平均模型
q阶滑动平均模型写作MA(q),说的是当前值是过去q个随机冲击的线性函数:
Xₜ = εₜ + θ₁εₜ₋₁ + θ₂εₜ₋₂ + … + θqεₜ₋q
MA模型捕捉的是过去的”意外”对当前值的影响。它特别适合建模市场对新闻事件的反应模式。
4.3 ARMA模型:两者结合
ARMA(p,q)模型把两个成分组合在一起:
Xₜ = φ₁Xₜ₋₁ + … + φₚXₜ₋ₚ + εₜ + θ₁εₜ₋₁ + … + θqεₜ₋q
对于非平稳序列,先做差分使其平稳,再套用ARMA,就得到了ARIMA(p,d,q),其中d是差分的阶数。
4.4 GARCH模型:给波动率建模
ARMA模型用在金融数据上有一个大问题:它假设波动率是恒定的。但金融市场有一个非常明显的特征:波动率聚集(Volatility Clustering):大的波动后面往往跟着大的波动,小的波动后面跟着小的波动。这叫做ARCH效应,是整个金融领域最 documented 的特征之一。
GARCH(1,1)模型通过将误差项的方差建模为一个随时间变化的量来解决这个问题:
σₜ² = ω + α₁εₜ₋₁² + β₁σₜ₋₁²
其中σₜ²是t时刻的条件方差,εₜ₋₁²是上一期的平方冲击,σₜ₋₁²是上一期的方差。这个模型精确地捕捉到了你在市场中观察到的波动率聚集现象:今天的大波动意味着明天也很可能有高波动。
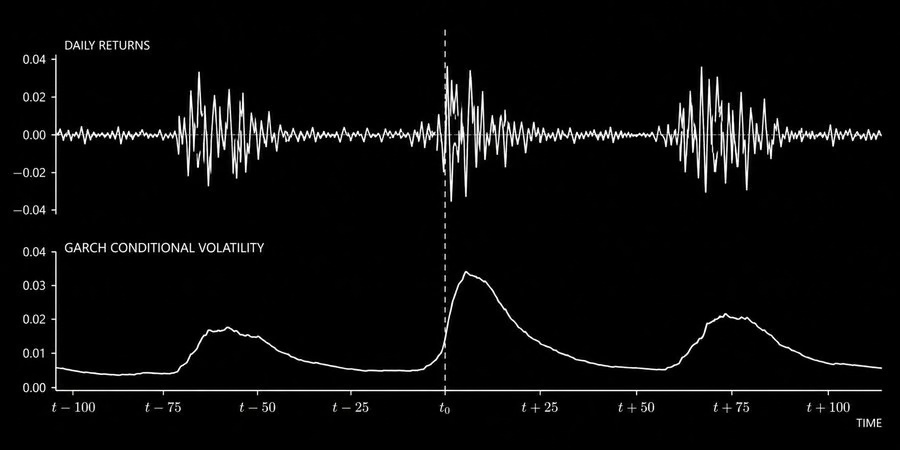
图: GARCH模型捕捉金融收益的关键特征:大波动后跟大波动,小波动后跟小波动
对于交易来说,GARCH的核心价值在于仓位管理。当σₜ²较高时,你应该降低仓位规模。当σₜ²较低时,你可以承担更多风险。仅靠这一个洞察,根据预估波动率动态调整仓位大小,就贡献了系统性基金产生的相当大比例的风险调整后收益。
| 模型 | 全称 | 核心功能 | 典型应用场景 |
|---|---|---|---|
| AR(p) | 自回归模型 | 捕捉历史值的线性依赖 | 短期动量/均值回复信号 |
| MA(q) | 滑动平均模型 | 捕捉历史冲击的影响 | 新闻事件后的反应建模 |
| ARMA(p,q) | 自回归滑动平均 | 结合两者 | 平稳序列的方向性信号 |
| ARIMA(p,d,q) | 差分ARMA | 先差分再ARMA | 非平稳序列建模 |
| GARCH(1,1) | 广义自回归条件异方差 | 动态波动率建模 | 仓位管理/风险控制 |
关键认知:即使方向无法准确预判,波动率也是可预测的。这是GARCH模型最重要的洞见,也是它在实际交易系统中不可替代的原因。
五、完整实现流程:从数据到信号的落地代码
这一节把前面所有内容组装成一个你今天就能在真实数据上运行的完整系统。
import numpy as np
import pandas as pd
import yfinance as yf
from statsmodels.tsa.arima.model import ARIMA
from arch import arch_model
from statsmodels.tsa.stattools import adfuller
import warnings
warnings.filterwarnings('ignore')
class TimeSeriesTradingSystem:
"""时间序列交易系统 — 完整实现"""
def __init__(self, ticker, period="5y"):
self.ticker = ticker
self.period = period
def fetch_and_prepare(self):
"""第一步:获取数据并计算对数收益率"""
data = yf.Ticker(self.ticker).history(period=self.period)
self.prices = data['Close']
# 计算对数收益率(百分比形式)
self.returns = np.log(
self.prices / self.prices.shift(1)
).dropna() * 100
return self.returns
def check_stationarity(self, series):
"""第二步:ADF平稳性检验"""
result = adfuller(series.dropna())
print(f"ADF Statistic: {result[0]:.4f}")
print(f"P-value: {result[1]:.4f}")
print(f"Stationary: {result[1] < 0.05}")
return result[1] < 0.05
def fit_arima_garch(self, returns,
arima_order=(1, 0, 1),
garch_order=(1, 1)):
"""第三步:拟合ARIMA + GARCH模型"""
arima = ARIMA(returns, order=arima_order)
arima_result = arima.fit()
residuals = arima_result.resid
garch = arch_model(
residuals, vol='Garch',
p=garch_order[0], q=garch_order[1]
)
garch_result = garch.fit(disp='off')
return arima_result, garch_result
def generate_signals(self, returns, lookback=252):
"""
第四步:滚动窗口生成交易信号
核心思路:
- 用ARIMA预测下一期方向
- 用GARCH预估下一期波动率
- 根据波动率反向调整仓位大小
"""
signals = []
for i in range(lookback, len(returns)):
window = returns.iloc[i-lookback:i]
try:
arima = ARIMA(window, order=(1, 0, 1)).fit()
forecast = arima.forecast(steps=1)[0]
garch = arch_model(
arima.resid, vol='Garch',
p=1, q=1
).fit(disp='off')
vol_forecast = np.sqrt(
garch.forecast(horizon=1)
.variance.values[-1][0]
)
# 方向信号:正预期→+1,负预期→-1
signal = 1 if forecast > 0 else -1
# 波动率倒数仓位缩放
position_size = min(
1.0, 1.0 / max(vol_forecast, 0.1)
)
scaled_signal = signal * position_size
except:
scaled_signal = 0
signals.append({
'date': returns.index[i],
'signal': scaled_signal
})
return pd.DataFrame(signals).set_index('date')
# ========== 运行完整流程 ==========
if __name__ == "__main__":
system = TimeSeriesTradingSystem("SPY")
returns = system.fetch_and_prepare()
print("Checking stationarity of returns:")
system.check_stationarity(returns)
arima_result, garch_result = system.fit_arima_garch(returns)
print(f"\nARIMA AIC: {arima_result.aic:.2f}")
print(f"GARCH Log-Likelihood: {garch_result.loglikelihood:.2f}")
# 生成信号并评估策略表现
signals = system.generate_signals(returns)
strategy_returns = (
signals['signal'].shift(1)
* returns.loc[signals.index]
)
sharpe = (
strategy_returns.mean()
/ strategy_returns.std() * np.sqrt(252)
)
cumulative = (1 + strategy_returns / 100).cumprod()
max_dd = (
(cumulative - cumulative.cummax())
/ cumulative.cummax()
).min()
print(f"\n=== System Performance ===")
print(f"Annualized Sharpe: {sharpe:.4f}")
print(f"Maximum Drawdown: {max_dd:.4f}")部署之前你必须理解的三件事
- GARCH仓位管理比ARIMA方向预测做得更多在高波动时期降低仓位暴露,是整个系统中最可靠的边际优势来源。60%准确率的方向信号配合波动率缩放仓位,比90%准确率的固定仓位产生更好的风险调整后收益。
- 滚动窗口结构是不可妥协的每一步你都在历史数据上拟合模型,往前推一步做预期。绝对不要在全量数据上拟合然后生成样本内预测还把它当成回测结果。那不是回测,那是贴标签。
- 替代数据是时间序列分析的天花板本文介绍的框架只捕捉价格序列内部的模式。持续跑赢市场的交易者使用的额外信息是价格序列不可能包含的东西:财报电话会议情绪、订单簿里的流量失衡、供应链数据、跨资产状态信息等。这些不是模型的改进,它们来自一个完全不同的信息集合。
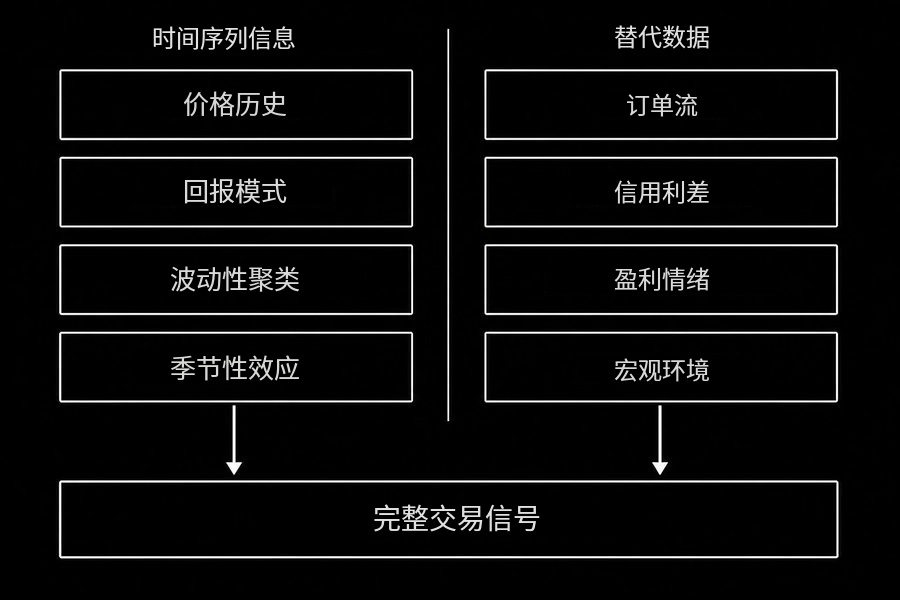
图:时间序列模型捕捉价格内部的模式,替代数据捕捉价格出现之前驱动底层过程的信息
最重要的实践限制
所有ARMA族模型都假设序列的统计特性在估计窗口内大致稳定。在金融市场中,这个假设经常被违反。标准的缓解措施是用252个交易日的滚动估计窗口:新数据进来就丢弃旧数据。更短的窗口适应更快但参数估计噪声更大;更长的窗口更稳定但对状态变化的反应滞后。最优窗口长度是一个经验问题,每个品种和每条策略都需要单独回答。
全文总结
时间序列分析并不预测未来。它做的事情是根据当前状态和已观测到的历史,产生数学上最优的未来期望值。当这个期望值在方向上有足够的正确频率,再配合波动率缩放的仓位管理,就能产生持续的边际优势。
完整的框架就在这篇文章里:建模之前先检验平稳性,始终用收益率而非价格作为输入,用ARIMA捕捉收益率自相关中的方向性信号,在上面叠加GARCH来跟踪波动率并动态调整仓位规模,用滚动步进法验证一切。同时要记住:最大的行情、那些创造或毁灭最多资金的行情,来自于现实层面的结构性变化,没有任何时间序列模型能提前看到。
最后这一点不是模型的缺陷,它是对现实的描述。历史上最成功的系统性策略团队,都清楚地知道自己的模型能做什么、不能做什么。他们把模型用在它真正擅长的地方。从稳定状态中提取稳定模式,然后用另类数据和状态监测来判断这些状态什么时候即将改变。
- 时间序列 = 趋势 + 季节性 + 冲击三成分,稳定性是一切前提。
- 三大任务:滤波(看现在)、平滑(看历史)、预期(看未来)。
- 预期不等于预测,期望值几乎永远不等于实际值,但平均正确就够了。
- 单位根是最大陷阱,必须在收益率(非价格)上建模,先用ADF检验。
- ARMA管方向,GARCH管波动率,两者结合才是完整方案。
#量化交易 #时间序列分析 #Python实战 #金融工程 #ARIMA模型 #GARCH模型 #风险管理 #算法交易 #数据分析 #老余捞鱼
Be First to Comment