作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:在财务预测领域,准确预测股票价格是一项具有挑战性但至关重要的任务。传统方法通常难以应对股票市场固有的波动性和复杂性。这篇文章介绍了一种创新方法,该方法将长短期记忆 (LSTM) 网络与基于评分的微调机制相结合,以增强股票价格预测。我们将以 Reliance Industries Limited 的股票作为我们的案例研究,展示这种方法如何潜在地提高预测准确性。
一、核心理念
受 RLHF 的启发,我们尝试在时间序列预测中应用相同的概念,RLHF的概念因为ChatGPT的出现,可能第一次出现在大多数人的眼里,RLHF 是 “Reinforcement Learning from Human Feedback” 的缩写,这是一种结合了强化学习和人类反馈的机器学习方法。在这种方法中,人工智能(AI)系统通过执行任务并接收人类评估者对其行为的反馈来学习。这种方法特别适用于那些难以用传统奖励函数明确定义任务成功与否的情况。回到正题,我们的方法围绕三个关键组成部分:
1. 用于初始股票价格预测的LSTM模型
2.评估这些预测质量的评分模型
3.使用评分模型的输出来优化 LSTM 性能的微调过程
通过集成这些组件,我们的目标是创建一个更具适应性和准确性的预测系统,从而更好地捕捉股价变动的细微差别。
二、架构概述
1. LSTM 模型:
我们系统的核心是 LSTM 神经网络。LSTM 特别适合于股票价格等时间序列数据,因为它们能够捕获数据中的长期依赖关系。我们的 LSTM 模型将一系列历史股票价格作为输入,并预测序列中的下一个价格。
2. 评分模型:
评分模型是一个单独的神经网络,旨在评估 LSTM 预测的质量。它采用原始价格序列和 LSTM 的预测作为输入,输出一个表示 LSTM 预测预测准确性的分数。
3. 微调机制:
该组件使用评分模型生成的分数来调整 LSTM 的训练过程。在微调过程中,从评分模型获得较高分数的预测会得到更大的权重,从而鼓励 LSTM 学习模式,从而获得更准确的预测。
三、工作流程
1. 数据准备:
我们首先使用 yfinance 库获取 Reliance Industries Limited 的历史股票价格数据。然后,这些数据被预处理并拆分为适合 LSTM 训练的序列。
2. 初始 LSTM 训练:
LSTM 模型在部分历史数据上进行训练。这为我们提供了一个能够做出合理股票价格预测的基准模型。
3. 评分模型训练:
我们使用另一部分数据来训练评分模型。该模型通过将 LSTM 的预测与实际股票价格进行比较来学习评估 LSTM 预测的质量。
4. 微调过程:
使用数据的第三部分,我们对 LSTM 模型进行微调。在此过程中,我们使用评分模型来评估每个预测。LSTM 的学习率会根据这些分数进行调整,使其能够更专注于改进评分模型认为不太准确的预测。
5. 评估:
最后,我们在测试集上评估原始 LSTM 和微调后的 LSTM 的性能,比较它们的预测以评估微调方法的有效性。
四、代码实现
让我们将代码分解为多个部分并详细解释每个部分。
1. 导入库并设置环境
import yfinance as yfimport numpy as npimport pandas as pdfrom sklearn.preprocessing import MinMaxScalerimport torch.nnimport torch.nn importtorch.optimas optim from torch.utils.data import TensorDataset, DataLoaderimport matplotlib.pyplot as pltdevice = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)print(f“Using device:{device}”)此部分导入所有必要的库。我们使用 yfinance 来获取股票数据,使用 numpy 和 pandas 进行数据操作,使用 sklearn 进行数据预处理,使用 torch 构建和训练神经网络,使用 matplotlib 进行可视化。我们还设置了 PyTorch 将用于计算的设备(CPU 或 GPU)。
2. 数据获取和预处理
reliance = yf.Ticker(“RELIANCE.NS”)data = reliance.history(period=”max”)[‘Close’].values.reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1))data_normalized = scaler.fit_transform(data)
def create_sequences(data, seq_length):sequences = []targets = []for i in range(len(data) — seq_length):seq = data[i:i+seq_length]target = data[i+seq_length]sequences.append(seq)targets.append(target)return np.array(sequences), np.array(targets)
seq_length = 60 # 60 days of historical dataX, y = create_sequences(data_normalized, seq_length)在这里,我们获取 Reliance Industries Limited 股票的历史收盘价。我们使用 MinMaxScaler 对数据进行归一化,以确保所有值都在 0 到 1 之间,这有助于训练神经网络。
“create_sequences”功能至关重要。它将我们的时间序列数据转换为适合 LSTM 训练的格式。对于每个数据点,它会创建一个前 60 天 (seq_length) 的序列作为输入,并以第二天的价格为目标。
3. 数据切分
lstm_split = int(0.5 * len(X))scoring_split = int(0.75 * len(X))
X_lstm, y_lstm = X[:lstm_split], y[:lstm_split]X_scoring, y_scoring = X[lstm_split:scoring_split], y[lstm_split:scoring_split]X_finetuning, y_finetuning = X[scoring_split:], y[scoring_split:]
lstm_train_split = int(0.8 * len(X_lstm))X_lstm_train, y_lstm_train = X_lstm[:lstm_train_split], y_lstm[:lstm_train_split]X_lstm_test, y_lstm_test = X_lstm[lstm_train_split:], y_lstm[lstm_train_split:]我们将数据分为三个主要部分:
1. LSTM 训练和测试
2.评分模型训练
3.微调
这确保了我们流程的每个阶段都使用单独的数据,防止数据泄露,并对我们的方法进行公平评估。
4. LSTM 模型定义
class LSTMModel(nn.Module): def __init__(self, input_size=1, hidden_size=50, num_layers=2, output_size=1): super(LSTMModel, self).__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x): h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) out, _ = self.lstm(x, (h0, c0)) out = self.fc(out[:, -1, :]) return out
lstm_model = LSTMModel().to(device)criterion = nn.MSELoss()optimizer = optim.Adam(lstm_model.parameters(), lr=0.001)这定义了我们的 LSTM 模型。它由一个 LSTM 层和一个全连接层组成。该模型采用一系列股票价格并输出单个预测价格。
5. LSTM 模型训练
def train_model(model, train_data, train_targets, epochs=50, batch_size=32): train_data = torch.FloatTensor(train_data).to(device) train_targets = torch.FloatTensor(train_targets).to(device) train_dataset = TensorDataset(train_data, train_targets) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
model.train() for epoch in range(epochs): for batch_X, batch_y in train_loader: optimizer.zero_grad() outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step()
if (epoch + 1) % 10 == 0: print(f’Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}’)
train_model(lstm_model, X_lstm_train, y_lstm_train)此函数处理 LSTM 模型的训练过程。它使用 DataLoader 对我们的数据进行批处理,这有助于高效训练,尤其是对于大型数据集。该模型针对指定数量的 epoch 进行训练,每 10 个 epoch 打印一次损失以监控进度。
6. LSTM评估函数
def predict_and_evaluate(model, X, y): model.eval() with torch.no_grad(): X = torch.FloatTensor(X).to(device) predictions = model(X).cpu().numpy()
y = scaler.inverse_transform(y.reshape(-1, 1)) predictions = scaler.inverse_transform(predictions.reshape(-1, 1))
mae = np.mean(np.abs(y — predictions)) mape = np.mean(np.abs((y — predictions) / y)) * 100
return predictions, mae, mape此函数用于进行预测和评估模型的性能。它计算两个重要指标:
1. 平均绝对误差 (MAE):这为我们提供了预测误差的平均幅度。
2. 平均绝对百分比误差 (MAPE):这提供了预测准确性的百分比度量
7. 评分模型实现
class ScoringModel(nn.Module):def __init__(self, input_size=seq_length+1, hidden_size=32, output_size=1): super(ScoringModel, self).__init__() self.fc1 = nn.Linear(input_size, hidden_size) self.fc2 = nn.Linear(hidden_size, output_size) self.relu = nn.ReLU() self.sigmoid = nn.Sigmoid()def forward(self, x): out = self.relu(self.fc1(x)) out = self.sigmoid(self.fc2(out)) return out scoring_model = ScoringModel().to(device) scoring_criterion = nn.MSELoss() scoring_optimizer = optim.Adam(scoring_model.parameters(), lr=0.001)评分模型是一个简单的前馈神经网络。它采用与 LSTM 的预测连接的原始价格序列作为输入。输出是介于 0 和 1 之间的分数,表示 LSTM 预测的预测准确性。
8. 为评分模型准备数据
def prepare_scoring_data(X, y): lstm_model.eval() with torch.no_grad(): X_tensor = torch.FloatTensor(X).to(device) predictions = lstm_model(X_tensor).cpu().numpy()
scoring_X = np.concatenate([X.reshape(X.shape[0], -1), predictions], axis=1) scoring_y = np.abs(y — predictions.reshape(-1, 1)) # Use absolute error as the score return scoring_X, scoring_y
X_scoring_train, y_scoring_train = prepare_scoring_data(X_scoring[:int(0.8*len(X_scoring))], y_scoring[:int(0.8*len(X_scoring))])X_scoring_test, y_scoring_test = prepare_scoring_data(X_scoring[int(0.8*len(X_scoring)):], y_scoring[int(0.8*len(X_scoring)):])此函数准备用于训练评分模型的数据。它使用 LSTM 对评分数据集进行预测,然后将这些预测与原始输入序列连接起来。评分模型的目标是 LSTM 预测的绝对误差。
9. 微调过程
def fine_tune_lstm(lstm_model, scoring_model, X, y, epochs=10, lr=0.0001): fine_tune_optimizer = optim.Adam(lstm_model.parameters(), lr=lr) X_tensor = torch.FloatTensor(X).to(device) y_tensor = torch.FloatTensor(y).to(device)
for epoch in range(epochs): lstm_model.train() total_loss = 0 for i in range(len(X)): fine_tune_optimizer.zero_grad() lstm_output = lstm_model(X_tensor[i].unsqueeze(0)) loss = criterion(lstm_output, y_tensor[i].unsqueeze(0))
# Get score from scoring model scoring_input = torch.cat([X_tensor[i].reshape(1, -1), lstm_output.detach()], dim=1) score = scoring_model(scoring_input)
# Adjust loss based on score adjusted_loss = loss * (1 + score.item()) adjusted_loss.backward() fine_tune_optimizer.step() total_loss += adjusted_loss.item()
if (epoch + 1) % 5 == 0: print(f’Fine-tuning Epoch [{epoch+1}/{epochs}], Avg Loss: {total_loss/len(X):.4f}’)
# Fine-tune LSTMfine_tune_lstm(lstm_model, scoring_model, X_finetune_train, y_finetune_train)这就是本文提到的关键。微调过程使用评分模型来调整 LSTM 的学习。对于每个预测,我们使用评分模型计算分数。然后,此分数用于调整损失-分数较低(表示准确性较低)的预测会导致较高的损失,从而鼓励模型更多地关注改进这些预测。
10. 评估和比较
现在我们既有了原始 LSTM 模型,又有了微调模型,我们可以比较它们在微调数据集上的性能。这种比较将有助于我们了解我们基于评分的微调方法是否确实改进了模型的预测。
# Predictions with original LSTM on fine-tuning datasetoriginal_finetune_train_preds, original_finetune_train_mae, original_finetune_train_mape = predict_and_evaluate(lstm_model, X_finetune_train, y_finetune_train)original_finetune_test_preds, original_finetune_test_mae, original_finetune_test_mape = predict_and_evaluate(lstm_model, X_finetune_test, y_finetune_test)
print(“\nOriginal LSTM on Fine-tuning Dataset:”)print(f”Train MAE: {original_finetune_train_mae:.2f}, MAPE: {original_finetune_train_mape:.2f}%”)print(f”Test MAE: {original_finetune_test_mae:.2f}, MAPE: {original_finetune_test_mape:.2f}%”)
# Evaluate fine-tuned modelfinetuned_train_preds, finetuned_train_mae, finetuned_train_mape = predict_and_evaluate(lstm_model, X_finetune_train, y_finetune_train)finetuned_test_preds, finetuned_test_mae, finetuned_test_mape = predict_and_evaluate(lstm_model, X_finetune_test, y_finetune_test)
print(“\nFine-tuned LSTM on Fine-tuning Dataset:”)print(f”Train MAE: {finetuned_train_mae:.2f}, MAPE: {finetuned_train_mape:.2f}%”)print(f”Test MAE: {finetuned_test_mae:.2f}, MAPE: {finetuned_test_mape:.2f}%”)此代码块在微调数据集(训练和测试拆分)上评估原始模型和微调的 LSTM 模型。我们计算每种情况的平均绝对误差 (MAE) 和平均绝对百分比误差 (MAPE)。
11. 可视化
为了更好地了解这些改进,我们可以将两个模型的预测与实际股票价格一起可视化。
plt.figure(figsize=(20, 15))
# Training set comparisonplt.subplot(2, 1, 1)plt.plot(scaler.inverse_transform(y_finetune_train), label=’Actual’, color=’black’)plt.plot(original_finetune_train_preds, label=’Original LSTM’, color=’blue’, alpha=0.7)plt.plot(finetuned_train_preds, label=’Fine-tuned LSTM’, color=’red’, alpha=0.7)plt.title(‘Predictions on Fine-tuning Training Set’)plt.legend()
# Test set comparisonplt.subplot(2, 1, 2)plt.plot(scaler.inverse_transform(y_finetune_test), label=’Actual’, color=’black’)plt.plot(original_finetune_test_preds, label=’Original LSTM’, color=’blue’, alpha=0.7)plt.plot(finetuned_test_preds, label=’Fine-tuned LSTM’, color=’red’, alpha=0.7)plt.title(‘Predictions on Fine-tuning Test Set’)plt.legend()
plt.tight_layout()plt.show()这将创建一个图,将实际股票价格与原始 LSTM 模型和微调 LSTM 模型的预测进行比较。这种可视化表示可以帮助我们确定微调后的模型在哪些方面进行了改进,哪些方面可能仍在苦苦挣扎。
12. 量化改进
为了清楚地了解我们的微调过程对模型的改进程度,我们可以计算评估指标中的改进百分比。
# Calculate improvement percentagestrain_mae_improvement = (original_finetune_train_mae — finetuned_train_mae) / original_finetune_train_mae * 100train_mape_improvement = (original_finetune_train_mape — finetuned_train_mape) / original_finetune_train_mape * 100test_mae_improvement = (original_finetune_test_mae — finetuned_test_mae) / original_finetune_test_mae * 100test_mape_improvement = (original_finetune_test_mape — finetuned_test_mape) / original_finetune_test_mape * 100
print(“\nImprovement after Fine-tuning:”)print(f”Train MAE Improvement: {train_mae_improvement:.2f}%”)print(f”Train MAPE Improvement: {train_mape_improvement:.2f}%”)print(f”Test MAE Improvement: {test_mae_improvement:.2f}%”)print(f”Test MAPE Improvement: {test_mape_improvement:.2f}%”)此代码计算并打印训练集和测试集的 MAE 和 MAPE 改进百分比。
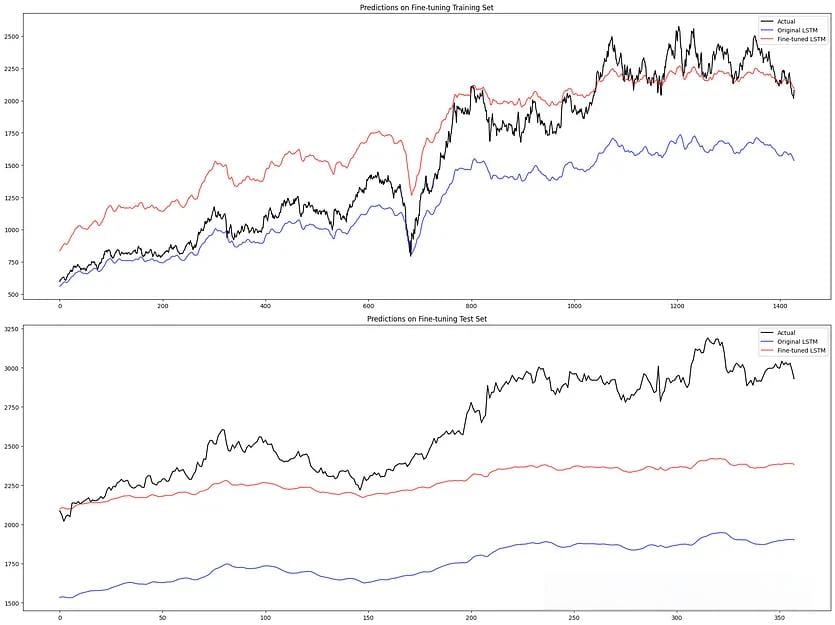
五、结果分析
基于微调数据集上的原始
LSTM 输出:训练 MAE:326.92,MAPE:17.98%,测试 MAE:860.84,MAPE:32.48%
微调数据集上的微调 LSTM:训练 MAE:246.51,MAPE:21.79%,测试 MAE:340.44,MAPE:12.20%
SBI
微调数据集上的原始 LSTM:训练 MAE:14.49,MAPE:3.88% 测试 MAE:67.14,MAPE:9.62%.
微调数据集上的微调 LSTM:训练 MAE:71.53,MAPE:27.42%测试 MAE:86.50,MAPE:11.62%.
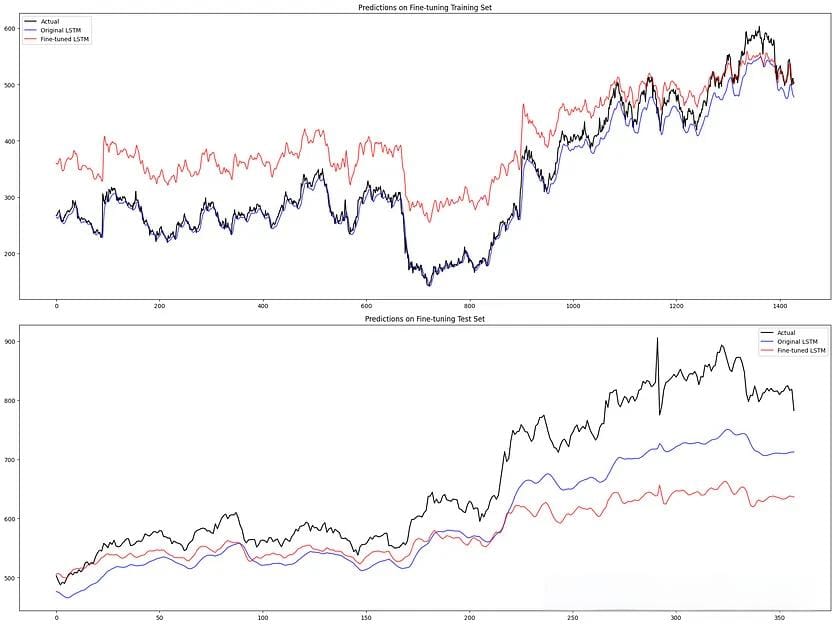
总之,我们可以看到 结果喜忧参半 。对于 Reliance,我们基于评分的微调方法显示出提高 LSTM 股票价格预测性能的前景,但 SBI 并非如此。因此,与任何机器学习模型一样,尤其是在金融领域,应谨慎使用并与其他分析工具和专业知识结合使用。此外,它是一个实验性架构,可能无法在所有场景中都有效。
六、代码
代码是外网直接开源在colab上的,感兴趣的朋友就不需要文中一点点的复制黏贴了,感谢开源。
import yfinance as yfimport numpy as npimport pandas as pdfrom sklearn.preprocessing import MinMaxScalerimport torchimport torch.nn as nnimport torch.optim as optimfrom torch.utils.data import TensorDataset, DataLoaderimport matplotlib.pyplot as plt
# Check if GPU is availabledevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"Using device: {device}")
# Fetch Reliance stock datareliance = yf.Ticker("SBIN.NS")data = reliance.history(period="max")['Close'].values.reshape(-1, 1)
# Normalize the datascaler = MinMaxScaler(feature_range=(0, 1))data_normalized = scaler.fit_transform(data)
def create_sequences(data, seq_length): sequences = [] targets = [] for i in range(len(data) - seq_length): seq = data[i:i+seq_length] target = data[i+seq_length] sequences.append(seq) targets.append(target) return np.array(sequences), np.array(targets)
# Parametersseq_length = 60 # 60 days of historical data
# Prepare data with sliding windowX, y = create_sequences(data_normalized, seq_length)
# Split data for LSTM, Scoring, and Fine-tuninglstm_split = int(0.5 * len(X))scoring_split = int(0.75 * len(X))
X_lstm, y_lstm = X[:lstm_split], y[:lstm_split]X_scoring, y_scoring = X[lstm_split:scoring_split], y[lstm_split:scoring_split]X_finetuning, y_finetuning = X[scoring_split:], y[scoring_split:]
# Further split LSTM data into train and testlstm_train_split = int(0.8 * len(X_lstm))X_lstm_train, y_lstm_train = X_lstm[:lstm_train_split], y_lstm[:lstm_train_split]X_lstm_test, y_lstm_test = X_lstm[lstm_train_split:], y_lstm[lstm_train_split:]
# LSTM Modelclass LSTMModel(nn.Module): def __init__(self, input_size=1, hidden_size=50, num_layers=2, output_size=1): super(LSTMModel, self).__init__() self.hidden_size = hidden_size self.num_layers = num_layers self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x): h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size).to(device) out, _ = self.lstm(x, (h0, c0)) out = self.fc(out[:, -1, :]) return out
lstm_model = LSTMModel().to(device)criterion = nn.MSELoss()optimizer = optim.Adam(lstm_model.parameters(), lr=0.001)
# Train LSTM modeldef train_model(model, train_data, train_targets, epochs=50, batch_size=32): train_data = torch.FloatTensor(train_data).to(device) train_targets = torch.FloatTensor(train_targets).to(device) train_dataset = TensorDataset(train_data, train_targets) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
model.train() for epoch in range(epochs): for batch_X, batch_y in train_loader: optimizer.zero_grad() outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step()
if (epoch + 1) % 10 == 0: print(f'Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}')
train_model(lstm_model, X_lstm_train, y_lstm_train)
# LSTM Predictions and Evaluationdef predict_and_evaluate(model, X, y): model.eval() with torch.no_grad(): X = torch.FloatTensor(X).to(device) predictions = model(X).cpu().numpy()
y = scaler.inverse_transform(y.reshape(-1, 1)) predictions = scaler.inverse_transform(predictions.reshape(-1, 1))
mae = np.mean(np.abs(y - predictions)) mape = np.mean(np.abs((y - predictions) / y)) * 100
return predictions, mae, mape
lstm_train_preds, lstm_train_mae, lstm_train_mape = predict_and_evaluate(lstm_model, X_lstm_train, y_lstm_train)lstm_test_preds, lstm_test_mae, lstm_test_mape = predict_and_evaluate(lstm_model, X_lstm_test, y_lstm_test)
print(f"LSTM Train MAE: {lstm_train_mae:.2f}, MAPE: {lstm_train_mape:.2f}%")print(f"LSTM Test MAE: {lstm_test_mae:.2f}, MAPE: {lstm_test_mape:.2f}%")
# Scoring Modelclass ScoringModel(nn.Module): def __init__(self, input_size=seq_length+1, hidden_size=32, output_size=1): super(ScoringModel, self).__init__() self.fc1 = nn.Linear(input_size, hidden_size) self.fc2 = nn.Linear(hidden_size, output_size) self.relu = nn.ReLU() self.sigmoid = nn.Sigmoid()
def forward(self, x): out = self.relu(self.fc1(x)) out = self.sigmoid(self.fc2(out)) return out
scoring_model = ScoringModel().to(device)scoring_criterion = nn.MSELoss()scoring_optimizer = optim.Adam(scoring_model.parameters(), lr=0.001)
# Prepare scoring datadef prepare_scoring_data(X, y): lstm_model.eval() with torch.no_grad(): X_tensor = torch.FloatTensor(X).to(device) predictions = lstm_model(X_tensor).cpu().numpy()
scoring_X = np.concatenate([X.reshape(X.shape[0], -1), predictions], axis=1) scoring_y = np.abs(y - predictions.reshape(-1, 1)) # Use absolute error as the score return scoring_X, scoring_y
X_scoring_train, y_scoring_train = prepare_scoring_data(X_scoring[:int(0.8*len(X_scoring))], y_scoring[:int(0.8*len(X_scoring))])X_scoring_test, y_scoring_test = prepare_scoring_data(X_scoring[int(0.8*len(X_scoring)):], y_scoring[int(0.8*len(X_scoring)):])
# Train scoring modeltrain_model(scoring_model, X_scoring_train, y_scoring_train, epochs=30)
# Fine-tuning functiondef fine_tune_lstm(lstm_model, scoring_model, X, y, epochs=10, lr=0.0001): fine_tune_optimizer = optim.Adam(lstm_model.parameters(), lr=lr) X_tensor = torch.FloatTensor(X).to(device) y_tensor = torch.FloatTensor(y).to(device)
for epoch in range(epochs): lstm_model.train() total_loss = 0 for i in range(len(X)): fine_tune_optimizer.zero_grad() lstm_output = lstm_model(X_tensor[i].unsqueeze(0)) loss = criterion(lstm_output, y_tensor[i].unsqueeze(0))
# Get score from scoring model scoring_input = torch.cat([X_tensor[i].reshape(1, -1), lstm_output.detach()], dim=1) score = scoring_model(scoring_input)
# Adjust loss based on score adjusted_loss = loss * (1 + score.item()) adjusted_loss.backward() fine_tune_optimizer.step() total_loss += adjusted_loss.item()
if (epoch + 1) % 5 == 0: print(f'Fine-tuning Epoch [{epoch+1}/{epochs}], Avg Loss: {total_loss/len(X):.4f}')
# Split fine-tuning dataX_finetune_train, y_finetune_train = X_finetuning[:int(0.8*len(X_finetuning))], y_finetuning[:int(0.8*len(X_finetuning))]X_finetune_test, y_finetune_test = X_finetuning[int(0.8*len(X_finetuning)):], y_finetuning[int(0.8*len(X_finetuning)):]
# Predictions with original LSTM on fine-tuning datasetoriginal_finetune_train_preds, original_finetune_train_mae, original_finetune_train_mape = predict_and_evaluate(lstm_model, X_finetune_train, y_finetune_train)original_finetune_test_preds, original_finetune_test_mae, original_finetune_test_mape = predict_and_evaluate(lstm_model, X_finetune_test, y_finetune_test)
print("\nOriginal LSTM on Fine-tuning Dataset:")print(f"Train MAE: {original_finetune_train_mae:.2f}, MAPE: {original_finetune_train_mape:.2f}%")print(f"Test MAE: {original_finetune_test_mae:.2f}, MAPE: {original_finetune_test_mape:.2f}%")
# Fine-tune LSTMfine_tune_lstm(lstm_model, scoring_model, X_finetune_train, y_finetune_train)
# Evaluate fine-tuned modelfinetuned_train_preds, finetuned_train_mae, finetuned_train_mape = predict_and_evaluate(lstm_model, X_finetune_train, y_finetune_train)finetuned_test_preds, finetuned_test_mae, finetuned_test_mape = predict_and_evaluate(lstm_model, X_finetune_test, y_finetune_test)
print("\nFine-tuned LSTM on Fine-tuning Dataset:")print(f"Train MAE: {finetuned_train_mae:.2f}, MAPE: {finetuned_train_mape:.2f}%")print(f"Test MAE: {finetuned_test_mae:.2f}, MAPE: {finetuned_test_mape:.2f}%")
# Plot resultsplt.figure(figsize=(20, 15))
# Training set comparisonplt.subplot(2, 1, 1)plt.plot(scaler.inverse_transform(y_finetune_train), label='Actual', color='black')plt.plot(original_finetune_train_preds, label='Original LSTM', color='blue', alpha=0.7)plt.plot(finetuned_train_preds, label='Fine-tuned LSTM', color='red', alpha=0.7)plt.title('Predictions on Fine-tuning Training Set')plt.legend()
# Test set comparisonplt.subplot(2, 1, 2)plt.plot(scaler.inverse_transform(y_finetune_test), label='Actual', color='black')plt.plot(original_finetune_test_preds, label='Original LSTM', color='blue', alpha=0.7)plt.plot(finetuned_test_preds, label='Fine-tuned LSTM', color='red', alpha=0.7)plt.title('Predictions on Fine-tuning Test Set')plt.legend()
plt.tight_layout()plt.show()
# Calculate improvement percentagestrain_mae_improvement = (original_finetune_train_mae - finetuned_train_mae) / original_finetune_train_mae * 100train_mape_improvement = (original_finetune_train_mape - finetuned_train_mape) / original_finetune_train_mape * 100test_mae_improvement = (original_finetune_test_mae - finetuned_test_mae) / original_finetune_test_mae * 100test_mape_improvement = (original_finetune_test_mape - finetuned_test_mape) / original_finetune_test_mape * 100
print("\nImprovement after Fine-tuning:")print(f"Train MAE Improvement: {train_mae_improvement:.2f}%")print(f"Train MAPE Improvement: {train_mape_improvement:.2f}%")print(f"Test MAE Improvement: {test_mae_improvement:.2f}%")print(f"Test MAPE Improvement: {test_mape_improvement:.2f}%")本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
转发请注明原作者和出处。
Be First to Comment