作者:老余捞鱼
原创不易,转载请标明出处及原作者。
写在前面的话:本文是一篇均值回归策略原理与实施详述。该策略基于资产价格回归历史平均水平,通过实际操作,利用 Python 和 yfinance 库获取标普 500 指数中最大 50 家公司的历史股票数据,并以 20 天移动平均线为基础。当股价低于均线阈值(如 2%)为买入信号,高于阈值为卖出信号。代码实现策略并经回溯测试后,收集股票性能指标,整理结果至 DataFrame ,并分析了该策略的实际表现。
一、什么是均值回归?
如果我们知道某一策略能够持续促成盈利交易,那将会如何?均值回归或许就是答案所在。此策略乃是建立在资产价格会回归至历史平均水平这一简单理念之上。倘若价格过高,那么极有可能下跌;倘若价格过低,那么极有可能上涨。
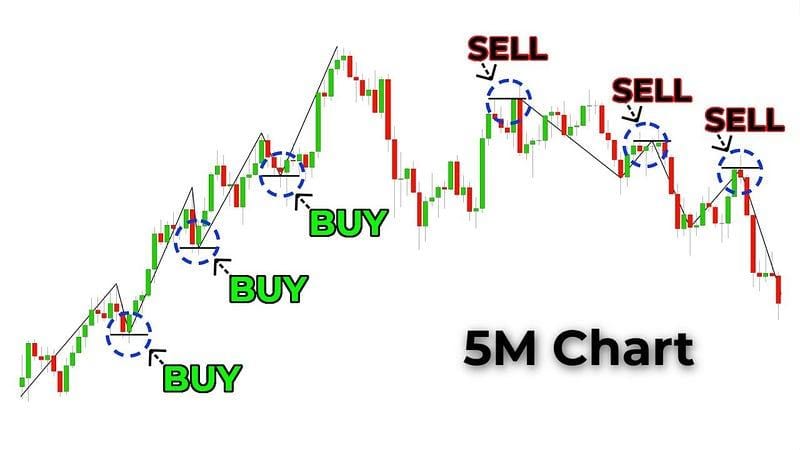
均值回归是一种交易策略,资产价格有望随着时间的推移回归到其平均值。这可以根据价格偏离移动平均线的情况识别买入和卖出信号。该策略基于移动平均数和标准偏差的计算方法,下图是特斯拉股票的平均回归示例。
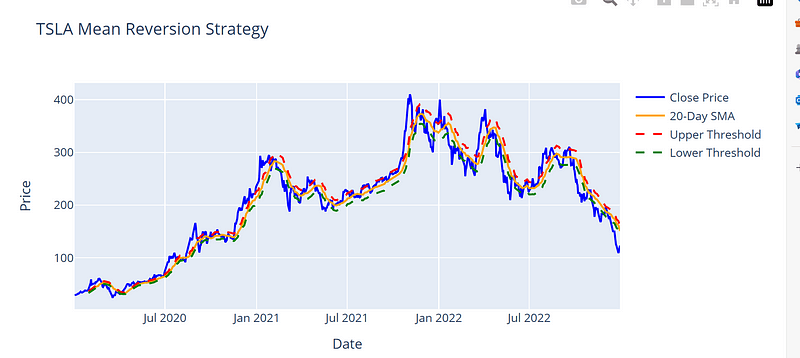
基本上,我们定义了一条均线,以 20 天均线为例,阈值定义为 2%,如果 de 的股票跌至 20 天均线的 2%,我们就买入,如果涨至 2%,我们就卖出。
二、实施均值回归战略
为了测试这一策略,我在标准普尔 500 指数中最大的 50 家公司上实施了这一策略,利用历史数据计算移动平均线并生成交易信号。
2.1 代码执行
import yfinance as yf
import pandas as pd
from backtesting import Backtest, Strategy
from backtesting.lib import crossover
from backtesting.test import SMA
import openpyxl
# List of top 50 S&P 500 companies by market cap (as of a specific date)
top_50_sp500 = [
'AAPL', 'MSFT', 'GOOGL', 'AMZN', 'META', 'BRK-B', 'TSLA', 'NVDA', 'JPM', 'JNJ',
'V', 'UNH', 'HD', 'PG', 'DIS', 'MA', 'PYPL', 'VZ', 'ADBE', 'NFLX',
'INTC', 'CMCSA', 'KO', 'PFE', 'PEP', 'T', 'XOM', 'CSCO', 'ABT', 'MRK',
'NKE', 'ABBV', 'CRM', 'AVGO', 'MCD', 'QCOM', 'TXN', 'ACN', 'MDT', 'COST',
'NEE', 'DHR', 'WMT', 'AMGN', 'HON', 'IBM', 'GE', 'LOW', 'CAT', 'BA'
]
# Parameters
start_date = '2020-01-01'
end_date = '2023-01-01'
moving_average_window = 20
threshold = 0.05 # 2% deviation from the mean
cash = 10000
commission = 0.002
# Define the mean reversion strategy
class MeanReversion(Strategy):
def init(self):
self.sma = self.I(SMA, self.data.Close, moving_average_window)
def next(self):
price_sma_diff = (self.data.Close[-1] - self.sma[-1]) / self.sma[-1]
if price_sma_diff < -threshold:
if not self.position:
self.buy()
elif price_sma_diff > threshold:
if not self.position:
self.sell()
elif abs(price_sma_diff) < threshold:
self.position.close()
# Function to run the backtest for a list of tickers
def run_backtests(tickers, start_date, end_date, moving_average_window, threshold, cash, commission):
all_metrics = []
for ticker in tickers:
try:
# Fetch historical data
data = yf.download(ticker, start=start_date, end=end_date)
if data.empty:
print(f"No data for {ticker}. Skipping...")
continue
# Prepare the data for backtesting
data['SMA'] = data['Close'].rolling(window=moving_average_window).mean()
data = data.dropna()
if data.empty:
print(f"Not enough data after rolling mean calculation for {ticker}. Skipping...")
continue
# Run the backtest
bt = Backtest(data, MeanReversion, cash=cash, commission=commission)
stats = bt.run()
# Collect metrics
metrics = {
"Stock": ticker,
"Start": stats['Start'],
"End": stats['End'],
"Duration": stats['Duration'],
"Equity Final [$]": stats['Equity Final [$]'],
"Equity Peak [$]": stats['Equity Peak [$]'],
"Return [%]": stats['Return [%]'],
"Buy & Hold Return [%]": stats['Buy & Hold Return [%]'],
"Max. Drawdown [%]": stats['Max. Drawdown [%]'],
"Avg. Drawdown [%]": stats['Avg. Drawdown [%]'],
"Max. Drawdown Duration": stats['Max. Drawdown Duration'],
"Trades": stats['# Trades'],
"Win Rate [%]": stats['Win Rate [%]'],
"Best Trade [%]": stats['Best Trade [%]'],
"Worst Trade [%]": stats['Worst Trade [%]'],
"Avg. Trade [%]": stats['Avg. Trade [%]'],
"Max. Trade Duration": stats['Max. Trade Duration'],
"Avg. Trade Duration": stats['Avg. Trade Duration'],
"Profit Factor": stats['Profit Factor'],
"Expectancy [%]": stats['Expectancy [%]'],
"Sharpe Ratio": stats['Sharpe Ratio'],
"Sortino Ratio": stats['Sortino Ratio'],
}
all_metrics.append(metrics)
except Exception as e:
print(f"Error processing {ticker}: {e}")
continue
# Convert to DataFrame
metrics_df = pd.DataFrame(all_metrics)
# Save to Excel
metrics_df.to_excel("top_50_sp500_mean_reversion_metrics.xlsx", index=False)
return metrics_df
# Run the backtests
metrics_df = run_backtests(top_50_sp500, start_date, end_date, moving_average_window, threshold, cash, commission)
# Print the results
print(metrics_df)本代码针对标普 500 指数前 50 家公司践行均值回归策略。它借助 yfinance 下载历史股票数据,算出 20 天移动平均线,并依价格偏离该平均线的状况生成买入 / 卖出信号。该策略运用回溯测试库展开回溯测试,收集每只股票的性能指标。结果会被编入 DataFrame 并保存至 Excel 文件以作分析。
2.2 相关库说明
安装这些库对于确保代码正常运行和利用其功能非常重要,这些功能可简化和增强技术分析和回溯测试过程。
yfinance: 雅虎财经库允许轻松高效地下载历史数据,这对分析和回溯测试交易策略至关重要。Backtesting: 回溯测试。便于模拟交易策略,提供一个测试和评估不同策略过去表现的环境。openpyxl: 用于将分析结果保存到 Excel 文件中,以便于查看和进一步分析获得的指标。
三、实验结果
得到的结果如图:
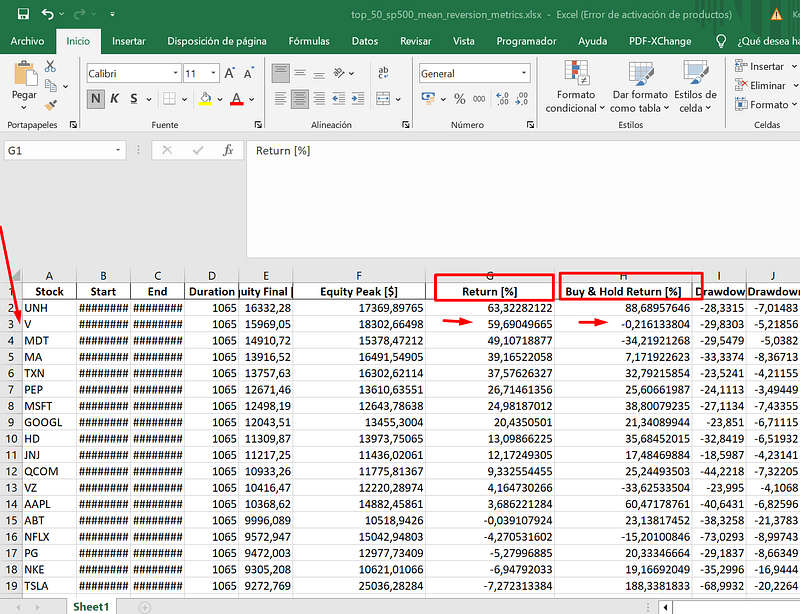
例如,我们在 Visa 股票中看到,买入并持有与使用均值回归策略之间存在巨大差异。
四、观点回顾
对于希望利用市场波动的交易者来说,使用 Python 实施均值回复策略是一个好的工具。在本文中,我们探讨了如何下载和预处理历史数据、计算移动平均线和阈值,以及如何根据这些计算结果生成买卖信号。
- 均值回归策略是一种基于价格回归到其平均值的交易策略,适用于认为资产价格会波动但最终会回到平均水平的市场。
- 通过对标准普尔500指数中最大的50家公司的股票数据进行回溯测试,该策略表现出了一定的实用性和效果。
- 策略的关键在于设置合适的移动平均窗口和阈值,以便及时地发出买入和卖出的信号。
- Python提供了强大的工具和库,如yfinance和backtesting,使得交易策略的测试和实施变得更加简便。
- 策略的回测结果显示,与简单的买入持有策略相比,均值回归策略在某些股票上可能会带来更高的回报和更低的风险。
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
转发请注明原作者和出处。
Be First to Comment