作者:老余捞鱼
原创不易,转载请标明出处及原作者。
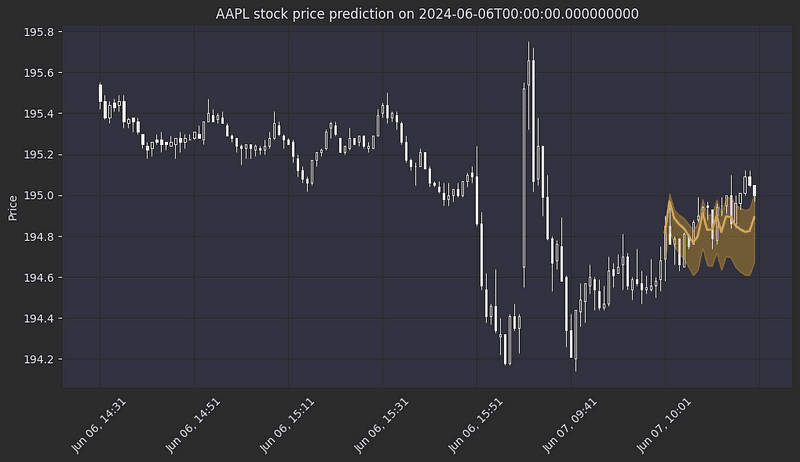
写在前面的话:今天我们继续探讨如何利用时态融合变换器(TFT)模型来预测股票的1分钟价格。本文是这个系列的第三篇文章,我们将继续探讨如何增强数据集,包括添加哪些关键技术指标,以及如何进行特征预处理,从而为模型训练做好准备。此外,我还会详细介绍TFT模型的设置和实现过程,以及它在股票交易预测中的独特优势。(封面图为TFT 预测 APPL 股票的示意)。
欢迎回到我们使用时态融合转换器构建高频股价预测模型的系列文章!本文结束时,您将知道如何:
- 利用 RSI、移动平均线和支撑/阻力水平等强大的技术指标来增强数据集。
- 对特征进行预处理,创建一个时间序列股票价格数据集,并在此基础上进行训练。
如果您还没有了解过第 1 部分和第 2 部分,请务必查看这两部分,以便为数据准备和市场微观结构分析打下坚实的基础。
本文是第二部分的延续,因此假定在此之前已经运行了第二部分提供的代码。我正在开发一个 github repo,其中将包含与这一系列文章相关的所有代码,敬请期待。
一、技术分析指标
1.1 移动平均线
移动平均线是技术分析的基本工具,通过平滑价格波动帮助交易者识别趋势。我们使用两种类型的移动平均线:简单移动平均线(SMA)用于分析长期趋势,而指数移动平均线(EMA)则用于更灵敏的日内分析。
简单移动平均线 (SMA):计算指定时间段内收盘价的非加权平均值,提供整体趋势的清晰视图。在日内交易中,日均线通常是一个重要的支点–如果处于上升趋势的股票开盘价低于均线,那么该水平在日内触及时通常会成为阻力位。相反,对于处于下降趋势的股票,如果开盘价高于均线,则该水平往往会在日内走势中提供支撑。
指数移动平均线 (EMA):对近期价格给予更多权重,使其对当前市场条件反应更灵敏。对于日内交易,EMA 能有效指示短期趋势,在上升趋势中起支撑作用,在下降趋势中起阻力作用。
利用这些移动平均线的一种流行策略是 “均值回归”,其原理是价格随着时间的推移往往会回归到其平均值。应用这种策略的日内交易者可能会在价格长期高于 EMA 时启动空头头寸,或在价格长期低于 EMA 时建立多头头寸。
1.2 支撑位和阻力位
支撑位和阻力位代表关键的价格点,市场心理往往会在这些价格点导致趋势逆转或盘整期。这些价位可以通过历史价格分析来确定,对每日和日内交易决策都很有价值。计算方法依赖于分形–价格图表中的局部最小值和最大值。
支撑位:也叫关键价位,买盘压力通常会增加的价位,可形成 “底线”,防止价格进一步下跌。
阻力位:历史上卖压加剧的价格区域,形成限制向上运动的 “天花板”。
1.3 相对强弱指数(RSI)
相对强弱指数(RSI)是一种动量震荡指标,可量化价格定向波动的速度和幅度。该指标在 0 和 100 之间震荡,有助于交易者识别潜在的反转点:
RSI > 70:超买信号,表明可能向下修正。
RSI < 30:表示超卖状态,暗示价格可能上行
我挑选这些特定指标是基于我个人的交易实践和对它们在我的策略中表现出的稳定性的认可。然而,在技术分析的广阔天地中,还有众多卓越的工具可供选择——从布林带、MACD,到成交量指标和市场情绪分析等。不同的交易风格和市场环境可能让您觉得其他指标更加契合您的模型需求。关键在于深入理解每个指标的长处与短板,并掌握它们如何在您的分析体系中相互补充、发挥作用。
二、代码实现
我会先定义几个辅助函数,使代码更加简洁。
import mplfinance as mpf
def get_daily_df(minute_df, agg_dict):
df_daily = resample_df(minute_df, "D", agg_dict)
return df_daily
def get_hourly_df(minute_df, agg_dict):
df_hourly = resample_df(minute_df, "H", agg_dict)
df_hourly["hour"] = df_hourly["datetime"].dt.hour
return df_hourly
def get_five_minute_df(minute_df, agg_dict):
df_five_minute = resample_df(minute_df, "5T", agg_dict)
return df_five_minute
def resample_df(df, resample_period, agg_dict):
resampled_df = df.groupby('symbol').resample(resample_period).agg(agg_dict).dropna()
resampled_df["symbol"] = resampled_df.index.get_level_values(0)
resampled_df["datetime"] = resampled_df.index.get_level_values(1)
resampled_df = resampled_df.reset_index(drop=True)
resampled_df["date"] = resampled_df["datetime"].dt.date
return resampled_df
def plot_bars_with_indicators(ohlc, ax, title: str, addplots=[]):
mpf.plot(
ohlc.rename({'open': 'Open', 'high': 'High', 'low': 'Low', 'close': 'Close'}, axis=1),
type='candle',
ax=ax,
addplot=addplots,
axtitle=title,
ylabel='Price',
style="yahoo"2.1 计算 EMA 和 SMA
ema_one_minute_bars = 9 * 5 # a common value for EMA lookback period is 45 minutes
sma_daily_bars = 50 # a common value for SMA lookback period on daily bars is 50 days
# Calculate the EMA and SMA
df['EMA'] = df.groupby(['symbol', 'date'])['close'].transform(lambda x: x.ewm(span=ema_one_minute_bars).mean())
df_daily = get_daily_df(df, {"close": "first"}) # we take the first close of each day to not "leak" future data into the minute bars
df_daily['SMA'] = df_daily.groupby('symbol')['close'].transform(lambda x: x.rolling(window=sma_daily_bars, min_periods=1).mean()) # very important to take the rolling moving average on the daily bars to avoid data leakage from future prices into current ones
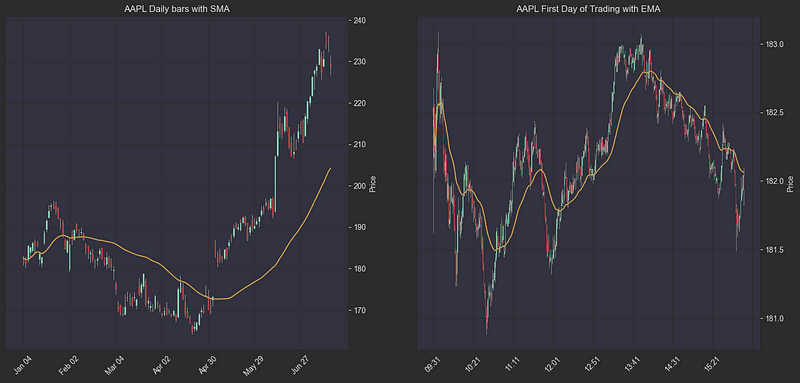
df = df.merge(df_daily[['symbol', 'date', 'SMA']], on=['symbol', 'date'], how='left').set_index(index).rename({'SMA': 'daily_sma'})我们可以在图表上绘制出这些平均线的样子,例如苹果公司的股票:
# Let's plot APPLE's daily bars with 50 day sma, and the first day of trading with 45 minute ema.
df_daily = get_daily_df(df, {"open": "first", "high": "max", "low": "min", "close": "last", "SMA": "mean"})
df_daily.set_index(pd.to_datetime(df_daily["date"]), inplace=True)
aapl_daily = df_daily[df_daily["symbol"] == "AAPL"][["open", "high", "low", "close", "SMA"]]
aapl_daily_sma = aapl_daily["SMA"]
aapl_minute = df[df["symbol"] == "AAPL"]
aapl_minute = aapl_minute[aapl_minute["date"] == df["date"].iloc[0]] # Plot the first day
aapl_minute_ema = aapl_minute["EMA"]
fig, (ax_daily, ax_minute) = plt.subplots(1, 2, figsize=(18, 8))
daily_addplot = mpf.make_addplot(aapl_daily_sma, panel=0, color='orange', ax=ax_daily)
minute_addplot = mpf.make_addplot(aapl_minute_ema, panel=0, color='orange', ax=ax_minute)
plot_bars_with_indicators(aapl_daily, ax_daily, title="AAPL Daily bars with SMA", addplots=[daily_addplot])
plot_bars_with_indicators(aapl_minute, ax_minute, title="AAPL First Day of Trading with EMA", addplots=[minute_addplot])
plt.show()AAPL图表上的移动平均线:
2.2 计算支撑线和阻力线(关键水平)
# resistances column holds the resistance levels (from the past) for each day
df_daily["resistances"] = df_daily.progress_apply(
lambda x: historic_resistances(
df_daily,
x["symbol"],
x["date"],
peak_rank_w_pct=0.03, # group peaks that are within 3% of the stock price
strong_peak_prominence_pct=0.05, # strong peaks have a prominence of at least 5%
strong_peak_distance=10, # strong peaks are at least 10 bars away from each other
peak_distance=5, # peaks are at least 5 bars away from each other
), axis=1
)
df_daily["supports"] = df_daily.progress_apply(
lambda x: historic_supports(
df_daily,
x["symbol"],
x["date"],
trough_rank_w_pct=0.03,
strong_trough_prominence_pct=0.05,
strong_trough_distance=10,
trough_distance=5,
), axis=1)
df_daily["resistances"] = df_daily.apply(lambda row: row["resistances"] if row["resistances"][0] > 0 else [], axis=1)
df_daily["supports"] = df_daily.apply(lambda row: row["supports"] if row["supports"][0] > 0 else [], axis=1)可以绘制几个示例,看看我们的关键水平是否合理:
def plot_with_resistances_and_supports(df, ax):
# Create a list to hold resistance line data
addplot = []
last_resistances = df.iloc[-1]["resistances"]
last_supports = df.iloc[-1]["supports"]
for resistance in last_resistances:
addplot.append(mpf.make_addplot([resistance] * len(df), color='red', ax=ax))
for support in last_supports:
addplot.append(mpf.make_addplot([support] * len(df), color='green', ax=ax))
# Plot the candlestick chart with resistance lines
mpf.plot(df, type='candle', addplot=addplot, style='charles',
volume=False, ax=ax)
# plotting support and resistance for stocks
symbols = df_daily.sample(2)["symbol"].values # sample 2 stock symbols
for symbol in symbols:
daily = df_daily[df_daily["symbol"] == symbol]
fig, ax = plt.subplots(figsize=(18, 8))
ax.set_title(f"{symbol} daily bars with resistance (red) and support (green) lines")
plot_with_resistances_and_supports(daily, ax)带有阻力线(红色)和支撑线(绿色)的 $JBLU 日线条形图:

带有阻力线(红色)和支撑线(绿色)的 $CRM 日线:
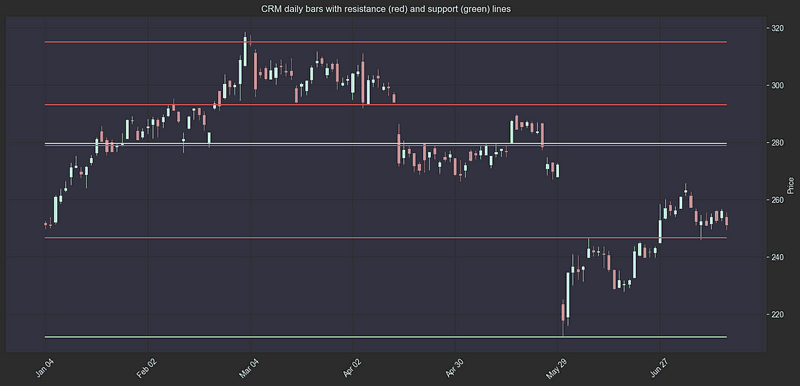
一旦股票收盘价高于阻力线或低于支撑线,支撑价就会变成阻力价,反之亦然。交易者不把这些水平当作 “阻力 “和 “支撑 “水平,而是称之为 “关键水平”。关键水平之所以重要,是因为它们更有可能成为支点。
我选择将这些水位称为 “关键水位”,而不区分支撑位和阻力位。
df_daily["key_levels"] = df_daily.apply(lambda x: x["resistances"] + x["supports"], axis=1)
df_daily.reset_index(inplace=True, drop=True)
index = df.index
df = df.merge(df_daily[['symbol', 'date', 'key_levels']], on=['symbol', 'date'], how='left').set_index(index)
df.set_index(index, inplace=True)2.3 计算 RSI
RSI 是一个很好的动量指标。它测量的是指定回溯窗口中平均绿色(上涨)柱和红色(下跌)柱之间的比率。对于我的模型,我选择的回看窗口大小为 30 条(代表 30 分钟),因为我们要处理的是高频预测。不过,理想的窗口大小可能有所不同,因为我没有尝试调整这些超参数。这只需使用 pandas-ta 软件包即可实现:
import pandas_ta as taWINDOW_SIZE = 30df['RSI'] = df.groupby('symbol')['close'].transform( lambda x: ta.rsi(x, window=WINDOW_SIZE)).fillna(50) # fillna 50 to represent neutral RSI2.4 缺口
缺口是股市中常见的现象。缺口是图表上价格之间的断裂,当股票价格急剧上涨或下跌,而中间没有交易时,就会出现缺口。造成缺口的原因有很多,如新闻、盈利报告或市场情绪。交易者通常会寻找缺口,因为它们可以提供良好的交易机会。缺口有四种类型:
- 常见缝隙:这些差距通常较小,通常很快就能填补。
- 突破缺口:当价格突破交易区间时,就会出现这种缺口。
- 失控缺口:这些缺口出现在强势趋势中,表明趋势可能会持续。
- 衰竭缺口:这些缺口出现在趋势的末端,预示着趋势有可能逆转。
缺口分析着重看的是每日缺口,即前一天收盘价与当天开盘价之间的差额。由于投资者对盈利报告的反应会使股票在盘前或盘后发生变动,因此缺口在盈利后非常常见。以跳空缺口开盘的股票通常会吸引大量日内交易者和投机者,从而使价格走势更加难以预测。我们将把当天的开盘跳空缺口(收盘价的对数百分比)作为一个特征添加到模型中。
daily_df = get_daily_df(df, {
"close": "last",
"open": "first",
"high": "max",
"low": "min",
"volume": "sum",
"average_volume": "first"
}).reset_index()
daily_df["previous_close"] = daily_df.groupby("symbol")["close"].shift(1).fillna(daily_df["close"])
daily_df["gap"] = np.log((daily_df["open"] - daily_df["previous_close"]) / daily_df["previous_close"])
df = df.merge(daily_df[["symbol", "date", "gap"]], on=["symbol", "date"], how="left").set_index(df_index)在本系列的最后一个专题(下一篇)中,我们将以类似于日线关键水平的方式添加小时关键水平:
#multi time frame analysis - find support and resistance on different time frames. We will use the key levels from daily hourly and 5 minute time frames.
hourly_df = get_hourly_df(df, {"close": "last", "high": "max", "low": "min"})
hourly_df["resistances"] = hourly_df.progress_apply(
lambda x: historic_resistances(
df_daily,
x["symbol"],
x["date"],
peak_rank_w_pct=0.005, # group peaks that are within 0.5% of the stock price
strong_peak_prominence_pct=0.02, # strong peaks have a prominence of at least 2%
strong_peak_distance=96, # strong peaks are at least 96 hours away from each other
peak_distance=4, # peaks are at least 4 hours away from each other
include_high=False
), axis=1
)
hourly_df["supports"] = hourly_df.progress_apply(
lambda x: historic_supports(
df_daily,
x["symbol"],
x["date"],
trough_rank_w_pct=0.005,
strong_trough_prominence_pct=0.02,
strong_trough_distance=96,
trough_distance=4,
include_low=False
), axis=1
)
hourly_df["key_levels"] = hourly_df.apply(lambda x: x["resistances"] + x["supports"], axis=1)
hourly_df["date"] = pd.to_datetime(hourly_df["date"])
df["date"] = pd.to_datetime(df["date"])
df = df.merge(hourly_df[["symbol", "date", "hour" , "key_levels"]], on=["symbol", "date", "hour"], how="left", suffixes=("","_hourly")).set_index(df_index)三、数据预处理
现在我们有了特征 DataFrame,需要对其进行预处理,以便模型能够有效地从中学习。金融时间序列建模的一个关键步骤是将原始价格数据转换为对数收益。对数收益计算公式为:
log_returns = np.log(price_t / price_t-1)
虽然我不会在这里深入探讨数学理论,但对数收益率与原始价格相比有几个关键优势:
静态性:对数收益通常比原始价格更稳定,因此更适合统计建模;
对称性:收益围绕零对称分布,有助于模型训练;
加法属性:与原始价格比不同,连续时期的收益可以相加;
规模独立性:对数收益率更易于比较不同股票,无论其价格水平如何。
预处理阶段还包括我们将要实施的其他几个关键步骤:
- 处理缺失值
- 功能缩放
- 创建符合时间顺序的训练/验证/测试分区
- 对 TFT 模型的数据进行排序
3.1 创建时间指数
pytorch_forecasting 软件包要求时间序列数据集中的每一行都有一个唯一的整数索引,代表其在序列中的位置。由于我们有多个时间序列(每只股票一个),因此我们按组计算该指数:
df["month"] = df["date"].dt.month
df["day"] = df["date"].dt.day
def create_time_idx(group):
# Use pd.factorize to create a continuous index for each symbol's time series
group['time_idx'] = pd.factorize(group.index)[0]
return group
df_index = df.index
df = df.groupby('symbol').apply(create_time_idx).reset_index(drop=True).set_index(df_index)3.2 处理关键水平(Key Levels)
关键水平目前以列表形式存储,模型无法直接处理。为了解决这个问题,我们为最近的支撑位和阻力位创建了单独的日线和小时线列:
def find_closest_resistance(row, col_name="key_levels"):
resistances = [level for level in row[col_name] if level > row["close"]]
if not resistances:
return row["high"]
return min(resistances)
def find_closest_support(row, col_name="key_levels"):
supports = [level for level in row[col_name] if level < row["close"]]
if not supports:
return row["low"]
return max(supports)
df["daily_key_level_above_current_price"] = df.apply(
find_closest_resistance,
axis=1
)
df["hourly_key_level_above_current_price"] = df.apply(
find_closest_resistance,
axis=1,
col_name="key_levels_hourly"
)
df["daily_key_level_below_current_price"] = df.apply(
find_closest_support,
axis=1
)
df["hourly_key_level_below_current_price"] = df.apply(
find_closest_support,
axis=1,
col_name="key_levels_hourly"
)3.3 特征归一化
为了使不同价格区间的股票特征正常化,我们将关键价位、EMA 和 SMA 转换为与当前价格的百分比差:
df["daily_key_level_above_current_price_change"] = df["daily_key_level_above_current_price"] / df["close"] - 1
df["daily_key_level_below_current_price_change"] = df["close"] / df["daily_key_level_below_current_price"] - 1
df["hourly_key_level_above_current_price_change"] = df["hourly_key_level_above_current_price"] / df["close"] - 1
df["hourly_key_level_below_current_price_change"] = df["close"] / df["hourly_key_level_below_current_price"] - 1
df["EMA_change"] = df["EMA"] / df["close"] - 1
df["SMA_change"] = df["SMA"] / df["close"] - 1在使用了原始形式的收盘价列之后,我将 close转换为对数收益率,并将其缩放 100(出于数值稳定性考虑,因为分钟级收益率非常小),然后去掉开盘价、最高价和最低价,代之以close_rank。计算公式为(close-low) / (high-low)(收盘价-最低价)/(最高价-最低价)。这样,我就可以将开盘价-高价-低价-收盘价柱状图中的信息提炼为单一指标。
df["close_rank"] = (df["close"] - df["low"]) / (df["high"] - df["low"]) # rank of the close price in the daily range
df["log_return"] = np.log(df.groupby("symbol")["close"].pct_change() + 1) * 100 # transform close prices to log returns
df["log_return"] = df["log_return"].fillna(0) # fill NaNs with 03.4 分类特征
时态融合转换器是为支持分类特征而构建的,因此我们需要将相关列转换为分类 pandas 类型:
# process categorical variables
df["month"] = df["month"].astype(str).astype("category")
df["hour"] = df["hour"].astype(str).astype("category")
df["minute"] = df["minute"].astype(str).astype("category")
df["industry"] = df["symbol"].apply(lambda x: fundamental_data[x]["industry"]).astype("category")
df["day_of_the_week"] = df["date"].dt.dayofweek.astype(str).astype("category")
df["is_earnings_day"] = df["is_earnings_day"].apply(lambda x: "yes" if x else "no").astype("category")3.5 数据筛选
为了降低成本,我将对数据进行筛选,只包含交易量最大的 20 只股票,这样模型训练就能花费合理的时间和计算量。
LIMIT_STOCKS = 20
top_20_average_volume_stocks = df.groupby("symbol")["average_volume"].mean().nlargest(LIMIT_STOCKS).index
df = df[df["symbol"].isin(top_20_average_volume_stocks)]
print(f"Top 20 stocks by average volume: {top_20_average_volume_stocks}")Top 20 stocks by average volume: Index(['NVDA', 'TSLA', 'AMD', 'PLTR', 'F', 'SOFI', 'AAPL', 'RIVN', 'INTC',
'AAL', 'PFE', 'CLSK', 'T', 'AMZN', 'CCL', 'UBER', 'MU', 'WFC', 'CMCSA',
'GOOG'],
dtype='object', name='symbol')3.6 数据分割
将数据分为训练集、验证集和测试集:
TRAIN_PERIOD_END = "2024-06-01"
VAL_PERIOD_END = "2024-06-10"
df_train = df[df["date"] < TRAIN_PERIOD_END]
df_val = df[(df["date"] >= TRAIN_PERIOD_END) & (df["date"] < VAL_PERIOD_END)]
df_test = df[df["date"] >= VAL_PERIOD_END]
print(f"Total train rows: {len(df_train)}, Total validation rows: {len(df_val)}, Total test rows: {len(df_test)}")Total train rows: 803394, Total validation rows: 38997, Total test rows: 199218这样我们就有了 5 个月的训练数据、10 天的验证数据和大约 1.5 个月的测试数据。
四、时空融合转换器设置
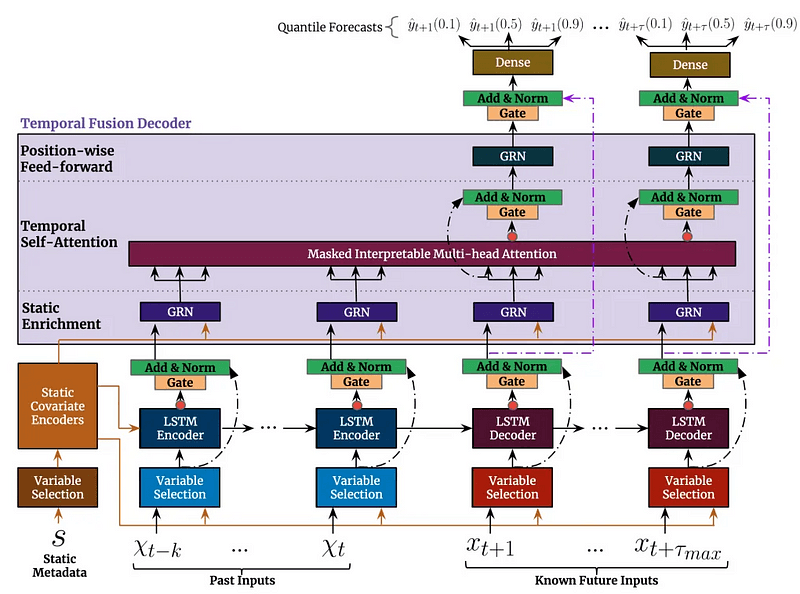
4.1 了解架构
时态融合变换器(Temporal Fusion Transformer,TFT)是一种复杂的深度学习架构,谷歌研究院在论文《Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting》中介绍了它。有兴趣的朋友可以去延展阅读下。
地址:https://arxiv.org/abs/1912.09363
4.2 主要组件和功能
1. 多类型变量处理
静态变量:行业部门或公司规模等不变特征。
时变已知:未来已知特征,如日历事件或预定收益日期。
时变未知:我们需要预测的特征,如价格走势和成交量。
2. 可解释的多头注意力
与传统不同,TFT 使用一种专门的注意力机制,使我们可以:
可视化历史时间点对每个预测的影响。
了解不同预测范围内特征的重要性。
确定模型学习识别的时间模式。
3. 变量选择网络(模型自动学习)
哪些特征对每个预测步骤都很重要。
特征的重要性在不同预测范围内如何变化。
何时更依赖近期数据,何时更依赖历史数据。
4. 多地平线预测
与 GPT 预测下一个令牌的方法类似,TFT 也能预测下一个令牌:
以自动回归方式预测未来的多个时间步长。
考虑不同时间跨度的不确定性水平。
为每次预测提供量化预测(置信)区间。
4.3 在股票交易中的实际应用
事实上 TFT 架构特别适合股票预测,因为:
- 它可以同时处理技术指标(时变)和基本数据(静态)。
- 关注机制有助于识别相关历史模式,类似于交易员寻找图表模式的方式
- 定量预测有助于评估风险和潜在的价格范围,对仓位大小至关重要。也可用于套利交易。
- 可解释性有助于验证模型是否在学习有意义的模式,而不是噪音。
现在让我们建立时间序列数据集(TimeSeriesDataset),它是训练 TFT 模型的基础。这种数据集结构专门设计用于处理时间数据的复杂要求,同时保持高效的批处理能力。
# if you haven't yet, run pip install pytorch_forecasting lightning
from pytorch_forecasting import Baseline, TemporalFusionTransformer, TimeSeriesDataSet
from pytorch_forecasting.data import GroupNormalizermin_prediction_length = max_prediction_length = 20 # 20 minutes
min_encoder_length = max_encoder_length = 240 # 4 hours
training_dataset = TimeSeriesDataSet(
df_train.reset_index(),
time_idx="time_idx",
target="log_return",
group_ids=["symbol"],
min_encoder_length=min_encoder_length,
max_encoder_length=max_encoder_length,
min_prediction_length=min_prediction_length,
max_prediction_length=max_prediction_length,
time_varying_known_reals=[
"time_idx", "average_volume"
],
time_varying_known_categoricals=[
"day_of_the_week", "is_earnings_day", "hour", "minute"
],
time_varying_unknown_reals=[
"close_rank", "rel_volume", "ATR", "EMA_change", "RSI", "SMA_change", "market_cap", "gap",
"log_daily_key_level_above_current_price_change", "log_daily_key_level_below_current_price_change",
"log_hourly_key_level_above_current_price_change", "log_hourly_key_level_below_current_price_change"
],
static_categoricals=[
"industry"
],
static_reals=[
"shares_float"
],
add_relative_time_idx=True,
add_encoder_length=False,
target_normalizer=None # targets are already normalized
)让我们来分析一下 TimeSeriesDataSet 配置的每个参数:
1. 核心参数
group_ids=["symbol"]: 标识数据集中不同的时间序列。在我们的例子中,我们有 20 种不同的股票,每个股票代码代表一个独立的时间序列,模型将学习如何预测。time_idx="time_idx": 代表数据点的顺序排列。这个整数索引必须在每只股票的时间序列中保持连续,并在预处理步骤中创建,以满足这一要求。target="log_return": 指定我们的预测目标,在本例中就是我们之前计算的对数收益。模型将尝试在预测范围内的每一步预测这个值。
2. 序列长度参数
min_encoder_length=240andmax_encoder_length=240: 设置模型在进行预测时能看到多少历史数据。我们将其固定为正好 4 小时(240 分钟)的数据,以确保每次预测的上下文一致。min_prediction_length=20andmax_prediction_length=20: 定义 20 分钟的预测范围。在实际预测中,我们通常会使用最大长度。
3. 特征分类
time_varying_known_reals=["time_idx", "average_volume"]: 这些是我们预先知道的数字特征,甚至是未来日期的数字特征。它们有助于模型理解时间模式,并纳入已知的未来信息。time_varying_known_categoricals=["day_of_the_week", "is_earnings_day", "hour", "minute"]: 这些是我们事先知道的分类特征,如日历信息和预定事件。它们有助于模型识别周期性模式和特殊市场条件。time_varying_unknown_reals: 包含我们的技术指标、市场数据和归一化关键水平。这些都是我们事先不知道的特征,必须对未来的时间戳进行预测或估算。static_categoricals=["industry"]andstatic_reals=["shares_float"]: 这些特征在整个时间序列中对每只股票保持不变。它们有助于模型根据每只股票的基本特征调整预测。
4. 高级功能
add_relative_time_idx=True:添加归一化时间索引特征,帮助模型理解序列中的相对时间位置。add_encoder_length=False: 由于我们使用的是 240 分钟的固定长度序列,因此已禁用添加序列长度功能。
该配置创建了一个数据集,为我们的模型提供 4 小时的历史数据,用于预测未来 20 分钟的收益。pytorch_forecasting 软件包会自动处理所有必要的缩放和特征归一化,使我们更容易专注于模型架构和交易策略,而不是数据预处理。这也是使用该软件包的主要优势之一–它可以抽象掉所有的时间序列数据准备工作,确保我们的特征得到正确的缩放和归一化,从而实现最佳的模型训练。
五、观点总结
在这篇文章中,我们介绍了使用时态融合转换器构建股票价格预测模型的基本基础工作。我们从移动平均线、支撑位/阻力位和 RSI 等基本技术指标入手,将原始价格数据转换为有意义的特征,并使用 pytorch_forecasting 建立了复杂的数据集结构。TFT 架构尤其适合这项任务,因为它可以处理多种类型的特征,同时提供带有置信区间的可解释预测。
股票价格预测的复杂性和不确定性:作者强调了股票价格预测的困难,并提醒读者这些预测不应被视为投资建议。
技术指标的重要性:技术指标如移动平均线、RSI和支撑阻力水平在构建预测模型中起着关键作用。
数据预处理的必要性:正确的数据预处理,包括将价格数据转换为对数收益率、归一化特征以及处理分类特征,对于提高模型性能至关重要。
时态融合变换器(TFT)的优势:TFT模型能够处理多种类型的特征,提供可解释的预测结果,并且能够进行多地平线预测,这使得它在股票交易预测中具有独特的优势。
模型解释性和风险管理:本文强调了模型预测的解释性,以及如何使用置信区间来管理交易风险。
六、预告
现在我们的特征工程管道和数据集结构已经就位,也已经准备好用机器学习来实现我们的交易策略。在第 4 部分(最后章节)中,我们将探讨所有组件是如何协同工作的:
- 如何使用 Tensorboard 在训练时间内训练模型并监控不同指标。
- 如何使用 pytorch_forecasting 的内置功能来解释模型的预测和关注模式。
- 根据不同指标评估模型。
- 实施最基本的交易策略并进行回溯测试。
感谢您阅读到最后,希望本文能给您带来新的收获。祝您投资顺利!如果对文中的内容有任何疑问,请给我留言,必复。
本文内容仅限技术探讨和学习,不构成任何投资建议
Be First to Comment