作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:大家好!今天我要与大家分享一个令人兴奋的话题:人工智能如何揭示股市中的隐藏模式。通过深入研究先进的K-means聚类算法,我们意外地发现了股市中五大独特的股票群体。这些群体不仅展现了市场的复杂性和多样性,还为投资者提供了更为精准的投资方向和策略。让我们一起来探寻其中的投资机会吧!
你是否好奇过股市里那些巨头公司之间可能存在的隐秘逻辑关系?现在,让我们一同探索一项颇具洞察力的分析研究,它借助机器学习的强大能力,揭开了市场中市值前50位股票之间不为人知的关联之谜。
一、什么是K均值聚类?
K均值聚类是一种广泛使用的无监督学习算法,主要用于数据聚类分析,适用于多种数据分析任务。它通过将数据点分组到 K 个预定义的簇中,帮助我们识别数据中的模式和结构。其工作流程通常包括以下几个步骤:
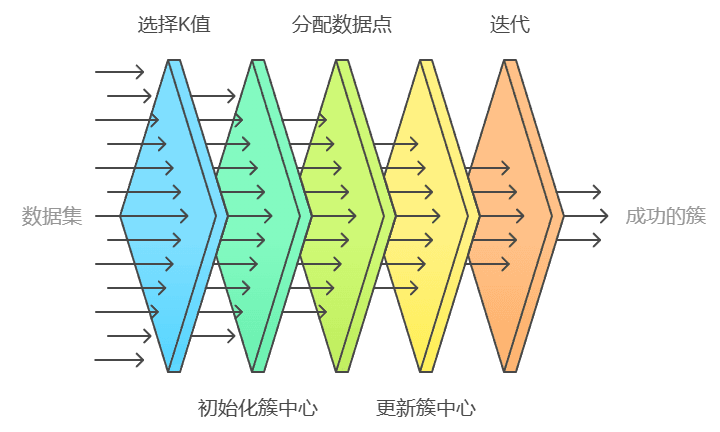
K均值聚类在多个领域中都有广泛的应用,包括但不限于:
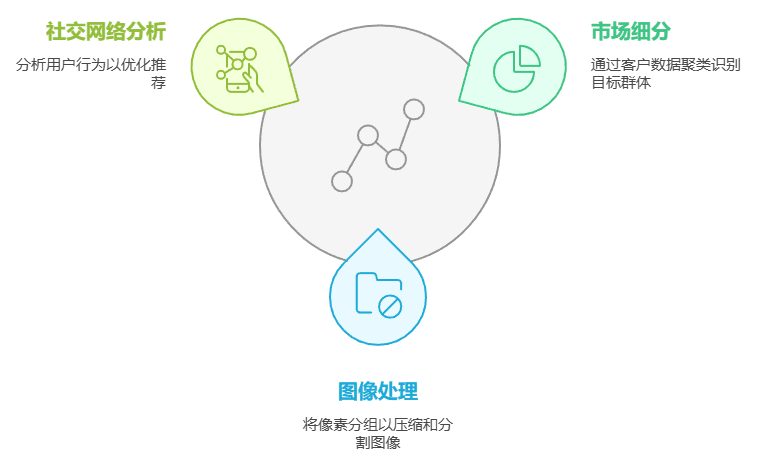
K均值聚类是一种简单而有效的聚类算法,适用于多种数据分析任务。尽管它在处理大规模数据集时表现良好,但也存在一些局限性,如对初始簇中心的敏感性和对噪声数据的脆弱性。因此,在实际应用中,选择合适的 K 值和预处理数据是至关重要的。
二、AI驱动聚类的力量
通过 K 均值聚类,我们在美股市场的重量级企业(市值前50位股票)中发现了五个不同的群体。
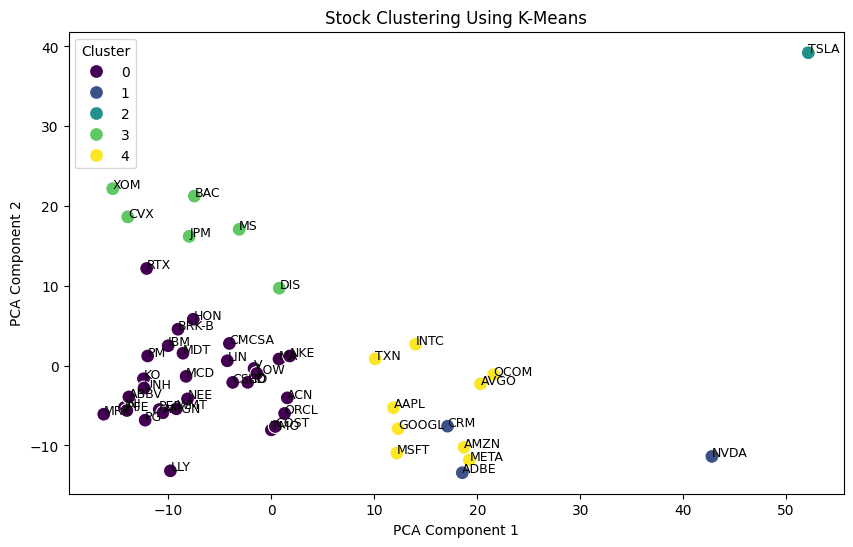
如上图所示,每个群组都讲述了各自独特的市场动态和行业关系。
2.1 表现稳定组
这些公司是股市的中坚力量(上图中的紫色圆点),具体包括这些:
- 消费品:可口可乐(”KO”)、百事可乐(”PEP”)、宝洁(”PG”)、麦当劳(”MCD”)。
- 医疗保健巨头:辉瑞(”PFE”)、默克(”MRK”)、礼来(”LLY”)、联合健康(”UNH”)。
- 蓝筹股:伯克希尔哈撒韦公司(”BRK-B”)、强生公司(”JNJ”)、沃尔玛公司(”WMT”)。
- 科技巨头(稳定版):甲骨文(”ORCL”)、思科(”CSCO”)、IBM。
AI 将它们聚类到一起的原因来自于这三点:
- 企业经营可靠、现金流充裕。
- 这些股票波动小,回报稳定。
- 在经济低迷时期,它们的表现往往优于其他产品,因此在不确定因素笼罩时,它们是投资者的最爱。
2.2 创新者组
AI 将它们聚类到一起的原因是高增长,所以称之为创新者((上图中的深蓝色圆点)。
包括:Meta(”META”)、NVIDIA(”NVDA”)、Adobe(”ADBE”)、Salesforce(”CRM”)。
聚类到一起的原因来自于这三点:
- 这些公司因创新而茁壮成长。
- 发展快速、迅猛,在人工智能、云计算和数字化转型的浪潮中乘风破浪。
- 它们很不稳定,但当整个市场很好时,回报是巨大的。
2.3 金融与能源组合
聚类算法发现这些股票与宏观经济趋势密切相关。比如金融、能源和工业类股票(上图中的浅绿色圆点)。
- 金融巨头:摩根士丹利(”MS”)、美国银行(”BAC”)、摩根大通(”JPM”)。
- 能源巨头:雪佛龙(”CVX”)、埃克森美孚(”XOM”)。
- 娱乐巨头:迪斯尼(”DIS”)。
聚类到一起的原因来自于这三点:
- 它们的表现与利率、油价和全球经济健康状况息息相关。
- 它们是周期性的,往往随着整体经济的起伏而起伏。
- 经济繁荣时,他们大放异彩,但经济衰退时就没那么好了。
2.4 科技巨头组
半导体和硬件技术在这里聚集,这一切都与芯片有关。这里汇聚了一些科技界的大腕(上图中的黄色圆点):
- AAPL 苹果
- MSFT 微软
- GOOGL 谷歌
- AMZN 加上 INTC、AVGO 和 TXN 等半导体企业
为什么聚类算法它们集中在一起?
- 这些股票共同受到半导体周期的影响。
- 它们的性能取决于对芯片、5G 和物联网设备的需求。
- 周期性强,但在科技时代具有巨大潜力。
2.5 孤狼组( The Lone Wolf )
AI 将特斯拉(”TSLA”)划到了一组(上图中的深绿色圆点,右上角),聚类算法给出的原因是:
- 特斯拉的波动性无与伦比,由创新、市场情绪和埃隆-马斯克驱动。
- 它们的回报模式与众不同,或者说是独树一帜。
三、功能实现
3.1 K-means 聚类
K-means 聚类就像组织一个派对,根据你的需求对它们进行分组。下面是工作原理:
- 首先,我们决定需要多少个组(在我们的例子中,需要 5 个组);
- 算法在数据中随机放置 5 个 “中心点”;
- 每只股票被分配到最近的中心;
- 将中心移至其所在组中所有股票的平均位置。
# Step 1: Prepare the data
scaler = StandardScaler()
returns_scaled = scaler.fit_transform(returns.T)
# Step 2: Apply K-Means Clustering
kmeans = KMeans(n_clusters=5, random_state=42)
clusters = kmeans.fit_predict(returns_scaled)K-means 优点包括:
- 易于理解和实施。
- 有效处理大型数据集。
- 创建清晰、独特的小组。
- 非常适合查找类似的股票行为。
3.2 主成分分析 (PCA)
想象一下你如何拍摄三维物体的照片:是不是先需要将其平面化为二维,同时保留尽可能多的细节。这就是 PCA!它将复杂的股票走势转化为我们可以直观看到的简单形式。
# Dimensionality Reduction using PCA
pca = PCA(n_components=2)
reduced_data = pca.fit_transform(returns_scaled)使用 PCA 的原因如下:
- 减少数据中的噪音。
- 它使模式更容易可视化。
- 处理 “维度诅咒”(curse of dimensionality)。
- 保留最重要的关系。
3.3 技术分析
- 我们使用每日收益率而不是价格,关注变动模式而不是绝对值。
- 数据标准化可确保不会有单一股票因其价格规模而在分析中占主导地位。
- random_state=42 可确保结果的可重复性。
- 两个 PCA 成分通常能捕捉到股票回报率 60-80% 的变化。
3.4 神奇的数字 5 簇
聚类分析中最头疼的问题之一是 :应该开几个组?让我们来看看为什么我们选择 5 个聚类…
K-means 聚类中的 “K “代表我们想要创建的组的数量。选择正确的 K 值就像侦探一样,既需要证据,也需要直觉。下面是我们如何确定最佳数量的方法:
inertias = []
K = range(1, 11)
for k in K:
kmeans = KMeans(n_clusters=k, random_state=42)
kmeans.fit(returns_scaled)
inertias.append(kmeans.inertia_)KMeans(n_clusters=k, random_state=42): 创建一个 K-Means 聚类模型,在范围(1,11)(1 到 10 个聚类)内的每个 k 值都有 k 个聚类。另外random_state=42可确保重现性。kmeans.fit(returns_scaled): 将 K-Means 模型拟合到经过预处理和缩放的数据(returns_scaled)中。inertia:(惯性):测量数据点到最近聚类中心的距离平方和。较低的惯性意味着集群更加紧凑。inertias.append(kmeans.inertia_): 存储每个 k 的惯性值。
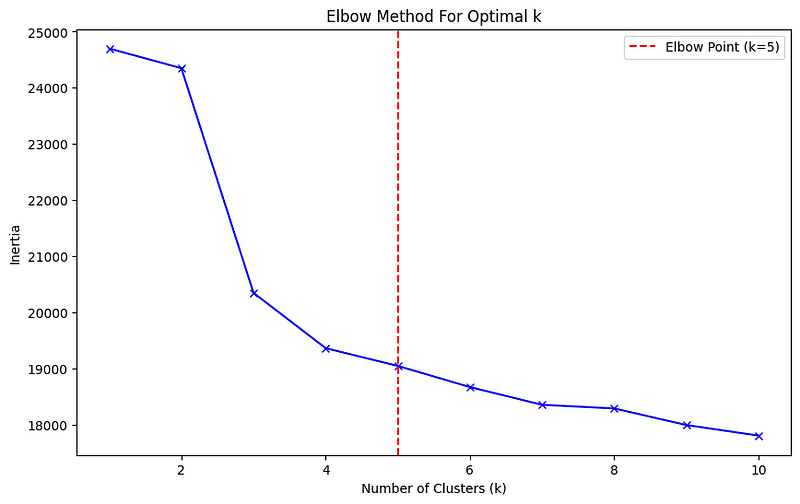
为什么选择 k=5?
- 肘部是惯性减小更慢的地方。
- 在肘部之前,增加更多的簇可显著降低惯性,表明紧凑性更好。
- 在弯头之后,增加更多的聚类会导致惯性减少,这往往与过度拟合相对应。
3.5 Try It Yourself
想要亲自试一下这个均值聚类分析?我完整的代码地址如下:
https://colab.research.google.com/drive/1pQsy-kNe10ARyG5gY_pk8xuuKQqtRtRT?usp=sharing
在我提供的colab notebook中,您可以尝试:
- 修改群组数量;
- 更改时间段;
- 添加或删除股票;
- 尝试不同的可视化技术;
- 运行聚类分析。
四、观点总结
这些群组聚类揭示了比传统行业分类更深层次的市场结构。这能否成为 2024 年及以后更智能地构建投资组合的关键?您在这些分组中发现了什么模式?您在交易中观察到过类似的相关性吗?我们可以一起讨论讨论。
- 多元化投资:真正的分散投资应该跨越不同的群组而非传统行业。
- 风险管理:了解每个群组对市场事件的反应有助于保护投资组合。
- 模式识别:群组内的股票价格变动往往相互关联,为交易机会提供线索。
- K-means聚类的优势:简单易懂,能有效处理大数据集,形成清晰的群组,适合发现相似股票行为。
- PCA的作用:减少数据噪音,使模式更易于可视化,处理维度诅咒,保留最重要的关系。
- 选择聚类数量的方法:通过观察惯性减少的速率,确定最佳的K值,通常选择在“肘部”之前的数值。
- 技术洞察:使用每日收益率而非价格,数据标准化,确保结果的可重复性,PCA成分通常捕捉到大部分股票回报率的变化。
- 未来展望:聚类分析可能是构建更智能投资组合的关键,能够揭示传统行业分类之下的市场结构。
感谢您阅读到最后,希望本文能给您带来新的收获。码字不易,请帮我点赞、分享。祝您投资顺利!如果对文中的内容有任何疑问,请给我留言,必复。
本文内容仅限技术探讨和学习,不构成任何投资建议
Be First to Comment