作者:老余捞鱼
原创不易,转载请标明出处及原作者。

写在前面的话:本文将深入探讨AI 机器学习在股票交易中的核心评估指标:精准率(Precision)、召回率(Recall)和F1分数(F1-Score)。这些指标不仅是量化交易中的关键工具,还能帮助我们优化交易策略,让投资决策更加科学和高效。如果你想借助AI技术提升交易胜率,掌握这些指标绝对是你的必修课!
一、三位一体的性能指标
在机器学习领域中,有三个指标堪称“王者”:精准率(Precision)、召回率(Recall)和F1分数(F1-Score)。它们不仅是模型性能的核心衡量标准,更是优化AI决策的利器。无论是股票交易还是其他应用场景,掌握这三个指标,你就能在机器学习的征途上所向披靡!
1.1 精准率(Precision)
想象你开发了一个垃圾邮件过滤器,任务是守护收件箱,将那些烦人的垃圾邮件统统挡在门外。精准率(Precision)会问你:“在你标记为垃圾邮件的所有邮件中,有多少是真正的垃圾邮件?”这个指标帮助你衡量过滤器的准确性,确保你不会误伤重要邮件。
其公式如下:
Precision = True Positives / (True Positives + False Positives)
= TP / (TP + FP)代码实践:
precision = precision_score(y_true, y_pred)
# Our sample showed: 0.75这意味着我们的初始预测有75%的准确率……表现不错,但仍有提升空间!通过优化模型或调整阈值,我们可以进一步提高精准率,减少误判,让过滤器的表现更上一层楼。
1.2 召回率(Recall)
如果说精准率关注的是“质量”,那么召回率(Recall)则更注重“完整性”。它会问你:“在所有垃圾邮件中,你成功拦截了多少?”召回率帮助你评估过滤器的覆盖能力,确保尽可能多的垃圾邮件被捕获,而不是漏网之鱼。
其公式如下:
Recall = True Positives / (True Positives + False Negatives)
= TP / (TP + FN)代码实践:
recall = recall_score(y_true, y_pred)
# Our sample showed: 0.60我们的过滤器目前只拦截了60%的垃圾邮件,这意味着仍有40%的“漏网之鱼”悄悄溜进了收件箱。这些鬼鬼祟祟的垃圾邮件不仅让人头疼,还可能带来风险。是时候优化模型,提高召回率,让这些“狡猾的家伙”无处可逃了!
1.3 F1分数(F1-Score)
但别急,我们的 F1分数就像一位智慧的朋友,总能找到精准率和召回率之间的完美平衡。它将这两个指标融合为一个单一的综合评分,帮你全面评估模型的性能。无论是追求精准还是覆盖全面,F1分数都能为你指明最优解。
其公式如下:
F1 = 2 * (Precision * Recall) / (Precision + Recall)
= 2 * ((TP / (TP + FP)) * (TP / (TP + FN))) / ((TP / (TP + FP)) + (TP / (TP + FN)))
代码实践:
f1 = f1_score(y_true, y_pred)
# Our sample showed: 0.671.4 宏观平均法
有时候,我们需要跳出细节,从全局视角审视问题。这正是宏观平均法(Macro-Averaging)的价值所在——它通过计算所有类别的平均值,帮助我们全面评估模型的整体表现,避免因某一类别的偏差而影响判断。
其公式如下:
Macro-Precision = (Precision_class1 + Precision_class2 + ... + Precision_classN) / N
Macro-Recall = (Recall_class1 + Recall_class2 + ... + Recall_classN) / N
Macro-F1 = (F1_class1 + F1_class2 + ... + F1_classN) / N
代码实践:
precision_macro, recall_macro, f1_macro, _ = precision_recall_fscore_support(y_true, y_pred, average='macro')宏观平均法(Macro-Averaging)的核心思想很简单:对所有类别的表现取平均值,无论类别的大小或样本数量如何。这种方法确保每个类别都被平等对待,特别适合当你希望所有类别都能得到同等重视的场景!
二、现实世界示例:二进制分类报告
让我们一起来分析一份真实的分类报告,通过拆解报告中的细节,我们可以更清晰地理解模型的性能表现,并找到优化的方向。
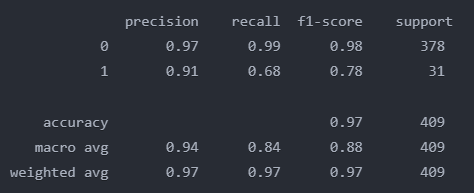
让我们来逐条分析……
2.1 Class 0 性能
- 精确度:0.97(97% 的预测 0 级实际为 0 级)
- 召回率:0.99(99% 的实际 0 类被正确识别)
- F1 分数:0.98(精确度和召回率之间的和谐平衡)
- 支持:378 个样本(这是我们占多数的班级)
2.2 Class 1 性能
- 精确度:0.91(91% 的预测 1 级实际为 1 级)
- 召回率:0.68(实际只有 68% )
- F1 分数:0.78(因召回率下降而降低)
- 支持:31 个样本(啊哈!我们有一个不平衡的数据集!)。
2.3 宏平均(Macro Average)
Precision: 0.94 = (0.97 + 0.91) / 2
Recall: 0.84 = (0.99 + 0.68) / 2
F1: 0.88 = (0.98 + 0.78) / 22.4 加权平均(Weighted Average)
Precision: 0.97 = (0.97 * 378/409 + 0.91 * 31/409)
Recall: 0.97 = (0.99 * 378/409 + 0.68 * 31/409)
F1: 0.97 = (0.98 * 378/409 + 0.78 * 31/409)你注意到什么有趣的现象了吗?我们的模型准确率高达97%……听起来简直不可思议,对吧?但别急着庆祝,仔细分析后你会发现,这个数字背后可能隐藏着一些关键问题。
- 我们有 378 个 0 类样本,只有 31 个 1 类样本(很不平衡吗?)
- 该模型在识别 0 级方面表现出色(99% 的召回率)
- 但在 1 类样本(68% 的回忆率)的学习中却很吃力。
这是一个典型的“准确性悖论”案例——高准确率并不总是等同于出色的性能!想象一下,如果这是一个医疗诊断模型,漏掉32%的阳性病例,后果可能是灾难性的。高准确率的背后,往往隐藏着严重的偏差和风险。
2.5 为什么需要不同的平均值?
为什么我们需要不同的平均值?因为现实世界的数据往往复杂多样,单一的平均值无法全面反映模型的性能。宏观平均法(Macro-Averaging)关注每个类别的平等性,而微观平均法(Micro-Averaging)则更注重整体数据的分布。选择合适的方法,才能更准确地评估模型的表现。
三、在股市预测中的应用
首先让我们以指标为例进行分析:
3.1 指标分析
precision recall f1-score support
Downturn 0.91 0.68 0.78 31
Normal 0.97 0.99 0.98 378这对交易意味着什么?
在正常市场条件下(0级),我们的模型能够准确识别99%的正常交易日,表现非常出色。这不仅有助于维持稳定的交易业务,还能最大限度地减少误报的下跌警报,避免不必要的市场恐慌。
在市场下滑(1类)的情况下,我们的模型预测下跌的准确率达到了91%,表现不俗。然而,它也漏掉了32%的实际衰退期,这意味着在熊市中,可能会错过关键的预警信号,带来高昂的代价!
3.2 “百万美元”的问题
交易者应该优先考虑哪个指标?答案取决于你的交易策略:
- 如果你更注重避免误报,精准率(Precision)是你的首选;
- 如果你希望尽可能捕捉所有市场机会,召回率(Recall)则更为重要;
- 而如果你追求两者的平衡,F1分数就是你的最佳伙伴。
请注意我们的数据分布:在409个交易日中,正常交易日占378天,而低迷日仅有31天。这种不均衡的数据分布意味着,模型可能会更倾向于预测“正常”情况,从而忽略少数但重要的低迷信号。
这真实反映了市场的典型行为:市场大多数时候保持稳定,但偶尔的剧烈波动(尽管罕见)却可能带来巨大影响。因此,模型必须能够有效处理这种数据不平衡,确保在关键时刻发出准确的预警。
3.3 源代码下载
源代码请从我的Google Colab中申请下载:
https://colab.research.google.com/drive/1CAa8vSeyn5xPRq43_btbonJHdJVbov-K?usp=sharing
四、观点总结
本文主要讲解了机器学习在股票交易中性能评估的关键指标:精确度(Precision)、召回率(Recall)和 F1 分数(F1-Score),并解释了这些指标的计算方法、实际应用以及在面对不平衡数据集时如何进行宏观和加权平均。
- 精确度、召回率和 F1 分数是评估机器学习模型性能的关键指标,它们能够帮助我们了解模型在不同情况下的表现。
- 在实际应用中,精确度和召回率可能会冲突,因此 F1 分数作为它们的调和平均值,能够提供一个更全面的性能评估。
- 不平衡数据集对模型性能评估有重要影响,宏观平均能够平等对待所有类别,而加权平均则考虑了类别大小的影响。
- 在股票市场预测中,选择合适的性能指标对于不同的交易策略至关重要。例如,保守型投资者可能更关注精确度,而风险厌恶型基金则可能更注重召回率。
感谢您阅读到最后,希望这篇文章为您带来了新的启发和实用的知识!如果觉得有帮助,请不吝点赞和分享,您的支持是我持续创作的动力。祝您投资顺利,收益长虹!如果对文中内容有任何疑问,欢迎留言,我会尽快回复!
本文内容仅限技术探讨和学习,不构成任何投资建议。
Be First to Comment